Pada artikel yang telah lama, kita sudah membahas secara konsepsi dan perumusan manual tentang cara untuk mengubah skala ukur data dari data ordinal ke interval. Perlu di garis bawahi bahwa penggunaan data dengan skala minimal interval banyak sekali keuntungan diantaranya keleluasaan dalam pemilihan alat statistik dan juga pengoperasioan berbagai macam operasi matematika. Successive !
Dalam banyak kasus metode regresi, path analisis dan SEM sering dihadapkan pada data ordinal dari hasil pengukuran dengan intrumen kuesioner dengan skala likert. Biasanya dibangun dua konsep pandangan pada data yang dihasilkan dari skala likert, pertama memandang interval dikarenakan pandangan dua kutub mistar (mirip dengan pola skala semantic), sehingga terhadap data hasil koding dapat secara langsung dilakukan analisis dengan rumpun statistik parametrik.
Dan kedua memandang tetap ordinal berdasarkan pandangan bahwa terdapat grading (peringkat) atas persepsi yang dipertanyakan pada skala likert, oleh karenanya untuk dapat digunakan pada alat statistik pada rumpun parametrik harus dikonversikan terlebih dahulu pada skala interval.
Pada kesempatan kali ini kita akan coba tunjukkan tahapan dalam penggunaan “add ins” MS excel yaitu method of Successive interval, yang banyak diperlukan oleh peneliti pemula untuk membantu mengkonversikan data hasil kuesionernya (skala likert) agar dapat digunakan pada alat statistik pada rumpun parametrik diantaranya regresi, path analisis atau pun SEM.
- Pastikan bahwa add ins method of Successive interval sudah di down load dan terpasang pada MS Excel.
- Lalu buka file excel yang terdapat data hasil entry kuesioner atau sejenisnya yang berisi data ordinal berskala likert (1 s.d 9) seperti tampak pada gambar berikut.

- Setelah terbuka file window excel, maka pada bagian menu excel (paling ujung biasanya) terdapat menu excel dan ketika di klik maka akan muncul pop up menu “Statistics” lalu klik dan akan muncul kembali menu pop up yang berisi daftar dari uji statistik pada excel, seperti tampak pada gambar berikut.

- Setelah dipastikan ada menu “Successive Interval” pada daftar menu “Statistics” tadi maka klik dan akan muncul tampilan jendela untuk memulai proses konversi skala ordinal data menjadi skala interval, seperti tampak pada gambar berikut.

- Langkah pertama adalah mendefinisikan “range” data pada sheet excel yang akan dikonversikan, dengan cara menginputkan pada cell “Range Data” lalu blok pada sheet excel data yang akan dikonversi. Dan pada cell “Output” klik pada bagian sheet excel yang kosong untuk dijadikan tempat memunculkan hasil konversi seperti tampak pada gambar berikut. Lalu klik “Next”.

- Langkah kedua adalah memilih variabel (no. pertanyaan) yang akan dikonversi, dengan cara memblok semua variabel (no. pertanyaan) yang tadi pada langkah sebelumnya (poin. 5) dipilih pada sheet excel, seperti tampak pada gambar berikut. Lalu klik “Next”.

- Langkah ketiga adalah memasukan interval nilai minimum “Min Value” dan maksimum “Max Value” yang peneliti gunakan dalam (skala likert) intrumen penelitiannya. (misal : 1 dan 5, atau 1 dan mx. 9), seperti tampak pada gambar berikut. Lalu pada centang menu “Display Summary”, seperti tampak pada gambar berikut. Setelanya klik “Finish”, lalu MS excel akan memulai proses konversi.

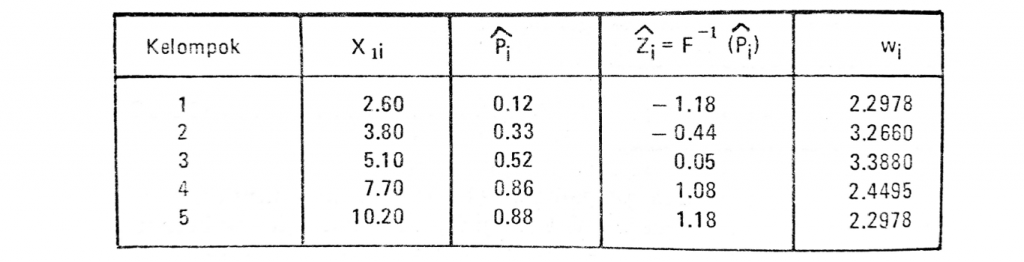
- Proses peng-konversian yang dilakukan MS excel terdiri dari dua bagian yaitu “Successive Details” dan “Successive Interval”. Dimana nilai yang nantinya akan digunakan sebagai nilai baru pengganti nilai yang lama adalah “Successive Interval”, sedangkan nilai-nilai yang terdapat pada “Successive Detail” adalah proses manual dalam perhitungan nilai konversi, seperti tampak pada gambar berikut.

Dengan adanya add ins pada menu excel khusus untuk metode Successive interval sangat membantu sekali bagi para peneliti atau data master untuk mempercepat proses pengolahan data yang dimilikinya. Yang perlu diperhatikan oleh peneliti atau data master sebelum melakukan peng-konversian adalah kehati-hatian dalam proses koding dari kuesioner ke dalam file excel, karena jika terjadi kesalahan dalam proses peng-entry-an dapat mengaburkan proses konversi yang dilakukan oleh MS excel. SEMANGAT MENCOBA!!!
———————————————————————————————————————————————————-
- Jika rekan peneliti memerlukan bantuan Survey Lapangan, Survey Online ataupun Olah Data dapat menghubungi mobilestatistik.com :
- WhatsApp : 081321709749
- Email : welcome@mobilestatistik.com
- Klik “Konsultasi Gratis” untuk mendapatkan informasi atau solusi terkait dengan pertanyaan-pertanyaan seputar metodologi penelitian.
- “1st Kirim Pertanyaan, Kami Jawab . . . InsyaAllah”
———————————————————————————————————————————————————-