Pada kesempatan yang lalu kita sudah praktekan cara membangun model faktor konfirmatori dan pembentukan model SEM dengan menggunakan software LISREL. Jika kita review ulang bahwa SEM terdiri dari penggabungan beberapa metode analisis statistika sekaligus diantaranya adalah regesi, analisi jalur dan analisis faktor konfirmatori. Bahwa variabel tidak dapat diukur secara langsung (model struktural) maka variabel-variabel tersebut diukur melalui variabel manifestnya (model pengukuran). Dan kesemua konsep tersebut dilakukan pemrosesannya dengan bantuan software LISREL.
Kurang lengkap rasanya jika kita tidak membahas proses pemodelan analisis jalur (model struktural dalam SEM) dengan menggunakan software LISREL. Secara garis besar prosesnya tidak jauh beda dengan proses pemodelan SEM. Mungkin saja artikel ini bisa digunakan sebagai pembanding hasil jika kita melakukan proses analisis jalur dengan menggunakan SPSS. Benefit utama jika kita menggunakan LISREL dalam pengolahan data untuk analisis jalur adalah kita tidak perlu secara manual menggambar pola jalur untuk kebutuhan interpretasi hasil, akan tetapi akan dihasilkan gambar pola jalur beserta koefisien dan signifikansi secara langsung pada output gambar yang LISREL sediakan. (sama halnya dengan output jika kita mengolah data CFA atau SEM).
Berikut kita uraikan tahapan penggunaan software LISREL untuk keperluan analisis jalur (path analysis) sebagai berikut :
Transfer Data Mentah
Buka program LISREL, lalu klik File, sehingga tampil kotak dialog berikut :
Klik Import Data, sehingga muncul tampilan berikut:
Pada menu List file of type pilih .sav dan pada menu Drives tempat menyimpan data SPSS untuk dimasukan ke dalam LISREL
Klik OK, maka dilayar monitor akan tampil berikut :
Pada menu utama, klik Data, pilih Define Variables, maka dimonitor akan tampil kotak dialog sebagai berikut :
Blok semua variabel seperti tampil kotak dialog berikut:
Selanjutnya klik Variable Type maka dilayar akan muncul tampilan berikut :
Plih Continous dan Aplly to all, kemudian klik OK. Sekarang telah lengkap data ditransfer ke program LISREL.
Komputasi Matriks Korelasi dan Uji Normalitas
Untuk memperoleh matriks korelasi dan uji normalitas, dari menu utama LISREL Windows Application, klik menu Statistics, pilih Output Options, sehingga muncul menu berikut :
Pada Moment Matrix pilih Correlations, pilih Save to File dan LISREL System Data, isikan nama file misal COR dan pilih Perform test of multivariate normality, seperti tampilan berikut :
Sekanjutnya klik OK, hasilnya adalah matriks korelasi langsung disimpan dalam file COR, sedangkan hasil uji normalitas ditunjukkan dalam keluaran sebagai berikut :
Membangun Diagram Jalur
Untuk membangun sebuah diagram jalur berdasarkan atas teori yang sudah ditetapkan sebelumnya dan sudah teridentifikasi klasifikasi jenis dari variabel-variabelnya, maka pada program LISREL pilih menu File lalu klik New, maka akan muncul tampilan jendela sebagai berikut :
Setelih dipilih menu Path Diagram kemudian klik OK maka akan muncul tampilan jendela kosong, lalu klik Setup untuk mengklasifikasikan variabel yang digunakan dalam model klik Variables. Perlu diperhatikan penggolongan variabel berdasarkan variabel independen dan variabel dependen yang digunakan dalam peneltian
Setelah semua variabel diklasifikasikan maka akan terlihat seperti pada jendela berikut ini dan siap untuk dibentuk menjadi model dalam diagram jalur.
Setelah semua variabel independen dan variabel dependen diklasifikasikan, klik Next untuk mendifinisikan sumber dan tipe data yang akan digunakan dalam pengolahan oleh program LISREL. Isikan pada Statistics from yaitu RAW Data atau Correlations. File Type yaitu PRELIS System Data dan pada File Name biarkan pilih file yang kita simpan .psf dan isikan jumlah sampel data pada Number of Observation. Jangan lupa Matrix to be analyzed pilih Correlations. Lalu klik OK.
Untuk proses pembuatan diagram jalur, kita tinggal men-drag atau menarik variabel-variabel yang ada pada daftar sebelah kiri ke jendela kosong sebelah kanan, lalu gunakan tools untuk membentuk korelasional atau jalur antar tiap variabel sesuai dengan kosep teoritisnya. Maka model diagram jalur yang sudah dibuat akan terlihat sebagai berikut :
Setelah seluruh variabel dipasangkan dengan dari variabel manifest ke masing-masing variabel latennya. Langkah selanjutnya adalah memproses diagram jalur dari data yang diinputkan dengan cara meng-klik gambar L (run Lisrel). Maka akan muncul jendela syntax program sebagai berikut :
Setelahnya klik kembali L (run Lisrel) maka akan muncul jendela berupa diagram jalur yang telah dilengkapi oleh program LISREL dengan nilai-nilai sepeti bobot faktor, koefisien jalur, erorr, t hitung. Seperti gambar berikut :
Koefisien Jalur
t-value
Dari hasil proses L (run Lisrel) tadi dihasilkan juga ouput Lisrel yang berisi hasil perhitungan secara lengkap baik itu statistik deskriptif, matriks korelasi, model koefisien path dan nilai-nilai GOF.
Dari hasil perhitungan data dengan menggunakan program LISREL di atas, dapat dikomparasikan dengan hasil perhitungan yang dihasilkan oleh software SPSS. Pastikan kedua hasil software menghasilkan hasil yang sama, jika berbeda, maka ada proses yang salah disalah satu software pengaplikasian data. SELAMAT MENCOBA!!
Kita lanjutkan pembahasan kita pada tools multivariate. Pada pembahasan terakhir kita sudah membahas secara komperhensif salah satu rumpun analisis multivariat yaitu analisis faktor eksploratori. Pada kesempatan kali ini kita akan membahas lanjutan salah satu tools lainnya yang termasuk dalam rumpun multivariat yaitu analisis diskriminan.
Jika kita sudah mengenal lebih dahulu konsep regresi yang salah satu tujuannya mengidentifikasi variabel X yang berpengaruh terhadap variabel Y pada suatu populasi, maka secara prinsip analisis diskriminan juga ditujukan pada tujuan yang serupa akan tetapi dalam perspektif populasi yang berbeda. Pada analisis diskriminan, konsepsi regresi tersebut diaplikasikan pada dua populasi yang berbeda yang dibentuk pada suatu model persamaan matematis yang sama. Sehingga pada analisis diskriminan salah satu tujuan utamanya adalah membentuk model persamaan matematis yang mengukur dependensi variabel, dimana variabel-variabel tersebut dapat menjadi pembeda yang sangat signifikan bagi populasi yang diperbandingkan.
Lebih lanjut akan kita bahasan secara konsepsi analisis diskriminan lebih lanjut pada bahasan berikut.
Konsep Umum
Pada dasarnya analisis diskriminan dapat dipergunakan untuk mengetahui variabel-variabel penciri yang membedakan kelompok-kelompok populasi yang ada dan juga dapat digunakan sebagai kriteria pengelompokan. Analisis diskriminan dilakukan berdasarkan perhitungan statistik terhadap kelompok yang terlebih dahulu diketahui secara jelas dan mantap pengelompokannya. Metode fungsi diskriminan pada awalnya dikembangkan oleh Ronald A. Fisher pada tahun 1936, sehingga fungsi diskriminan yang dibangun sering disebut pula sebagai fungsi diskriminan linear fisher.
Dalam sebuah paper yang berjudul “The Use of Multiple Measurements in Taxonomic Problems”, Fisher menyatakan bahwa apabila dua atau lebih populasi telah diukur dalam beberapa karakter X1, X2, … , Xp , maka dapt dibangun fungsi linear tertentu dari pengukuran itu di mana fungsi itu merupakan fungsi pembeda (pemisah) terbaik bagi populasi-populasi yang dipelajari. Fungsi linear yang dibangun disebut sebagai fungsi dikriminan.
Analisis Diksriminan Dua Kelompok
Semisal kita memiliki dua kelompok populasi yang bebas (independen). Dari populasi pertama diambil secara acak sampel berukuran n1 dan mempelajari p buah sifat dari sampel tersebut. Kemudian dari populasi keduua diambil secara acak sampel berukuran n2 dan mempelajari p buah sifat dari sampel tersebut. Dengan demikian ukuran sampel secara keseluruhan dari populasi pertama dan kedua adalah n1 + n2 = n. Misalkan p buah sifat yang dipelajari dari masing-masing populasi dinyatakan dalam variabel acak berdimensi ganda melalui vektor X = (X1, X2, … , Xp).
Sebelum membangun fungsi diskriminan, maka kita perlu melakukan pengujian perbedaan vektor nilai rata-rata dari kedua populasi untuk mengetahhui apakah ada nilai rata-rata dari sifat yang dipelajari (p) berbeda. Oleh karena fungsi diskriminan pada dibangun untuk menerangkan perbedaan di antara populasi, maka seyogianya fungsi diskriminan baru akan dibangun apabila uji perbedaan vektor rata-rata (uji beda) di antara populasi menunjukkan hasil yang nyata secara statistik. Untuk menguji perbedaan vektor nilai rata-rata diantara dua populasi dapat menggunakan Statistik T2 –Hotteling. Dengan hipotesis yang dapat dirumuskan sebagai berikut :
H0 : U1 = U2 ; artinya vektor nilai rata-rata dari populasi ke-1 sama dengan rata-rata dari populasi ke-2
H1 : U1 ≠ U2 ; artinya vektor nilai rata-rata dari populasi ke-1 dengan populasi ke-2 berbeda
Jika pengujian terhadap hipotesis di atas menolak H0 maka hal ini menunjukkan bahwa kedua nilai rata-rata dari sifat yang dipelajari adalah berbeda, dengan demikian kita dapat membangun fungsi diskriminan untuk mengkaji perbedaan sifat-sifat yang ada diantara kedua populasi yang dipelajari. Jika keadaan sebaliknya berlaku, dimana hasil pengujian terhadap hipotesis di atas menerima H0 maka fungsi diskriminan tidak layak untuk dibangun karena tidak ada perbedaan sifat-sifat di antara dua populasi yang sedang dipelajari.
Dengan demikian, kita boleh memandang bahwa pada dasarnya analisis diskriminan merupakan kelanjutan dari analisis perbedaan vektor nilai rata-rata dari kedua populasi yang dipelajari. Jadi dalam hal ini, fungsi diskriminan yang dibangun adalah untuk mencirikan perbedaan sifat-sifat yang ada dalam populasi. Dan dalam hal ini kita dapat membangun fungsi diskriminan linear Fisher.
Aturan Penggolongan Skor Diskriminan
Setidaknya terdapat dua cara penggolongan yang dapat dilakukan terhadap skor yang dihasilkan oleh fungsi diskriminan. Seperti yang telah kita uraikan sebelumnya bahwa salah satu dari fungsi analisis diskriminan adalah penggolongan suatu objek berdasarkan skor diskriminan yang dihasilkannya, termasuk pada kelompok populasi pertama ataukah populasi kedua. Berikut dua rumusan dalam pengkategorian skor diskriminan,
Penggolongan berdasarkan nilai rata-rata tengah antara dua populasi (m). Kriteria pertama, alokasikan individu (objek) dengan pengamatan X ke dalam kelompok (populasi) 1, jika Y0 > m atau Y0 – m > 0. Kriteria kedua, alokasikan individu (objek) dengan pengamatan X ke dalam kelompok (populasi) 2, jika Y0 ≤ m atau Y0 – m ≤ 0.
Penggolongan berdasarkan Statistic Wald-Anderson (W). Kriteria pertama, alokasikan individu (objek) dengan pengamatan X ke dalam kelompok (populasi) 1, jika W > 0. Kriteria kedua, alokasikan individu (objek) dengan pengamatan X ke dalam kelompok (populasi) 2, jika W ≤ 0.
Langkah-langkah Analisis Diskriminan
Setelah kita pahami fungsi atau kegunaan ataupun konsep dari analisis diskriminan pada penjelasan sebelumnya, ada baiknya kita coba urutkan kembali tahapan atau kriteria apa saja yang harus dilakukan oleh peneliti ataupun data master dalam melakukan analisis diskriminan, berikut kita coba resume beberapa tahapan atau kriterianya,
Fungsi diskriminan merupakan fungsi linear dari karakteristik (X) yang dibentuk dalam sebuah persamaan yang merupakan representasi dari 2 atau lebih populasi yang diperbandingkan.
Identifikasi terlebih dahulu sejumlah karakteristik (X) yang akan diperbandingkan dari 2 atau lebih populasi.
Uji beda T2 –Hotteling untuk memastikan bahwa karekteristik (X) dari 2 atau lebih populasi yang diperbandingkan berbeda secara statistik.
Bentuk fungsi linear diskriminan Fisher : Y = aX1 + bX2 + … + zXp.
Uji signifikansi karakteristik (X) dalam model diskriminan untuk memastikan bahwa karakteristik (X) dalam model diskriminan signifikan sebagai pembeda dari 2 atau lebih populasi.
Hitung nilai R2 antara karakteristik (X) dengan fungsi diskriminan (Y) untuk mendapatkan besaran nilai kontribusi masing-masing karakteristik (X) pada model diskriminan yang terbentuk.
Proses iterasi (pengulangan perhitungan) jika dalam proses pembentukan model diskriminan didapati ada karakteristik (X) yang tidak signifikan bagi model diskriminan, sampai dipastikan karakteristik (X) yang tersisa pada model diskriminan merupakan karakteristik (X) yang signifikan.
Hitung skor diskriminan dan lakukan pengelompokan objek baru berdasarkan kriteria pengelompokan nilai rata-rata tengah (m) ataupun statistik Wald-Anderson (W).
Yang perlu diperhatikan oleh peneliti atau data master pada tahapan-tahapan di atas adalah pada poin 7. Proses perhitungan (jika dilakukan manual) dilakukan berulang dari proses awal perhitungan pembentukan model diskriminan, jadi perlu diperhatikan secara khusus, agar diperoleh model diskriminan yang optimal dalam membedakan 2 atau lebih populasi.
Pada kesempatan selanjutkan kita akan coba uraikan tahapan dalam melakukan analisis diskriminan dengan bantuan software SPSS, agar dapat melihat secara sederhana proses perhitungan fungsi dari model linear diskriminan pada data yang kita miliki. Sebagai catatan perlu dipahami secara benar tentang penggunaan dan fungsi dari analisis diskriminan, agar tidak terjadi kekeliruan pengaplikasian pada data yang dimiliki oleh peneliti atau data master. SEMANGAT MEMAHAMI!!.
Pada bahasan analisis faktor eksploratori sebelumnya kita sudah banyak membahas terkait konsepsi, kegunaan dan fungsi dari analisis faktor eksploratori itu sendiri. Tahapan implementasi data pada software SPSS dalam menghasilkan faktor-faktor yang dimaksudkan juga sudah kita perlihatkan pada bahasan sebelumnya. Sehingga berharap apa yang sudah kita paparkan pada pembahasan sebelumnya dapat membantu para peneliti dalam proses memahami dan praktek pada data yang dimilikinya.
Beberapa pemahaman yang harus kita ulang-ulang bahwa ada kemiripan pada analisis faktor eksploratori dan analisis faktor konfirmatori (bahasan secara konsepsi narasi, tidak sebagai konsepsi matematis). Pada bahasan eksploratori perlakuan terhadapa variabel-variabel yang ada adalah dalam rangka menemukan sebuah pola variabel yang mengelompok yang berkontribusi dalam pembentukan suatu faktor (belum berlandaskan teori yang pasti), sehingga belum ditetapkannya suatu konsepsi variabel laten dan variabel manifest. Sedangkan pada konfirmatori semua konsep variabel sudah ditentukan berdasarkan teori yang sudah ditetapkan berdasarkan literatur dan dikenal sedari awal bahwa faktor/variabel induk tidak dapat di ukur secara langsung sehingga dikenal istilah variabel laten dan variabel manifest.
Dengan gambaran tersebut diharapkan para peneliti tidak salah dalam menentukan software pembantu dalam menganalisis datanya. SPSS banyak digunakan dalam analisis faktor eksploratori dan LISREL (sejenisnya) banyak digunakan dalam analisis faktor konfirmatori.
Pada kesempatan kali ini kita akan coba menjelaskan konsepsi rotasi yang muncul pada pembahasan analisis faktor ekploratori. Pada proses aplikasi pada software SPSS kita dituntut pula untuk memilih jenis rotasi yang akan dilakukan pada data yang dimiliki dengan tujuan mendapatkan kombinasi variabel penyusun faktor yang optimal.
Tujuan Rotasi Faktor
Tujuan utama dari dilakukannya proses rotasi pada proses pembentukan faktor pada analisis faktor eksploratori adalah untuk mendapatkan struktur faktor (kombinasi linear dari variabel-variabel dengan nilai faktor loadingnya) yang lebih sederhana dan dapat sangat membantu dalam proses interpretasi oleh para peneliti.
Secara teoritis proses rotasi dalam pendekatan matematis (matriks) terdiri dari 2 (dua) pendekatan yaitu orthgonal rotation dan oblique rotation (secara matematis tidak akan dibahas dalam artikel ini). Umumnya untuk memudahkan interpretasi para peneliti menggunakan pendekatan orthogonal rotation dalam proses pembentukan faktor dari analisis faktor. Dan pada kesempatan kali ini kita akan coba menerangkan dua (2) jenis pendekatan dalam rumpun rotasi orthogonal yaitu Varimax Roration dan Quantimax Rotation.
Sekali yang perlu diperhatikan dan dipahami oleh para peneliti atau data master adalah fungsi rotasi yang bertujuan untuk mengoptimalkan dihasilkannya kombinasi linear variabel-variabel dalam suatu faktor (1 atau 2 faktor) yang terbentuk dari hasil analisis faktor dan hal ini diindikasikan dengan mudahnya peneliti mengidentifikasi faktor terbentuk atas kontribusi besar (loading faktor) variabel-variabel penyusunnya.
Gambar 1. Menu Rotasi pada Software SPSS
Varimax Rotation
Dalam rotasi varimax tujuan utamanya adalah untuk mendapatkan struktur faktor yang terdiri dari kombinasi variabel-variabel yang memiliki nilai faktor loading yang sangat tinggi hanya pada satu faktor. Dengan demikian jika terbentuk lebih dari satu faktor maka nilai variabel loading suatu variabel pada satu faktor akan sangat tinggi dan pada faktor lainnya mendekati nol.
Oleh karenanya, hasil struktur faktor dengan menggunakan pendekatan rotasi varimax dapat dengan mudah dibedakan dengan struktur faktor yang lainnya (antar faktor terbentuk berdasarkan kombinasi variabel-variabel pembentuknya).
Quartimax Rotation
Dalama rotasi quantimax terdapat 2 (dua) tujuan utama diantaranya pertama, semua variabel memiliki nilai loading relatif tinggi berimbang pada satu faktor dan kedua, tiap variabel memiliki nilai loading yang tinggi pada satu faktor dibanding faktor yang lainnya serta memiliki loading mendekati nol (0) pada faktor lainnya tersebut.
Berdasarkan pemaparan kedua jenis rotasi sebelumnya, maka dengan jelas bahwa pada rotasi quatimax akan di dapat dua klasifikasi faktor diantaranya adalah pertama, suatu struktur faktor yang akan mewakili satu faktor yang dapat dianggap mewakili keseluruhan faktor (general factor) dan kedua, faktor lainnya yang terbentuk merupakan suatu konstruk yang spesifik. Oleh karenanya, rotasi quantimax sangat cocok jika digunakan apabila peneliti mencurigai sedari awal, kehadiran dari suatu “faktor umum” (merujuk pada hasil pertama). Dan hal ini bertentangan dengan rotasi varimax yang mengasumsikan bahwa faktor umum dihilangkan dan seharusnya tidak digunakan ketika teridikasi adanya faktor umum tersebut.
Sedikit gambar tentang rotasi pada analisis faktor eksploratori pada pembahasan sebelumnya diharapkan dapat membantu para peneliti atau data master untuk melakukan treatment pada data yang akan dianalisis secara tepat, sehingga dihasilkan faktor yang optimal sebagaimana dimaksudkan dalam tujuan penelitian yang sudah ditetapkannya. SEMANGAT MEMAHAMI!!!
Secara teoritis kita sudah sedikit banyak membahas secara konsepsi dan fungsi dari analisis faktor. Pada kesempatan kali ini kita akan coba uraikan tahapan penggunaan software SPSS dalam melakukan analisis faktor pada data yang kita miliki. Perlu diperhatikan oleh para peneliti adalah pemahaman secara teoritis apa itu analisis faktor dan komponen pengujian apa saja yang terdapat didalamnya, agar proses praktek yang dilakukan pada SPSS tidak membuat bingung peneliti itu sendiri.
Kita sarankan sebelum melakukan praktek dengan menggunakan SPSS, bagi yang baru saja menemukan artikel ini untuk membaca dan memahami artikel yang sudah kita tuliskan sebelumnya diantaranya, baca artikel : Analisis Komponen Utama (AKU), Analisis Faktor Ekploratori dan Kriteria Kebaikan Analisis Faktor Eksploratori. Hal ini penting agar mempermudah peneliti dalam memahami setiap tahapan yang akan kita paparkan pada pembahasan berikutnya.
Karena salah satu metode dalam analisis faktor adalah komponen utama, maka dalam proses pengaplikasiannya pada SPSS sama persis dengan tahapan yang dilakukan pada pengujian analisis komponen utama (baca artikel : Analisis Komponen Utama Dengan SPSS), perbedaannya terletak pada beberapa pemilihan menu tambahan yaitu pada uji kebaikan data dan optimasi pembentukan faktor dengan melibatkan rotasi. Secara lebih lengkap akan dipaparkan pada bagian berikut ini.
Buka software SPSS lalu masukan data penelitian yang kita punya pada jendela Data View dan definisikan variabel yang kita punya di jendela Variabel View.
Pastikan aturan yang sudah dikemukakan pada artikel sebelumnya dilakukan. Apabila satuan dari data kita berbeda lakukan standarisasi terlebih dahulu pada data yang kita punya.
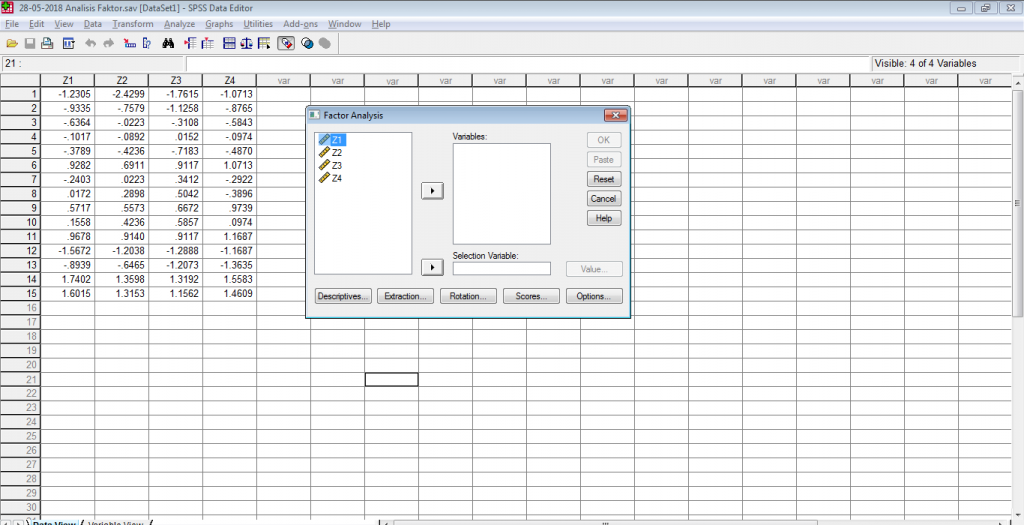
Setelahnya klik pada menu Analyse, pilih menu Data Reduction dan Factor lalu klik, maka akan muncul jendela seperti gambar berikut.
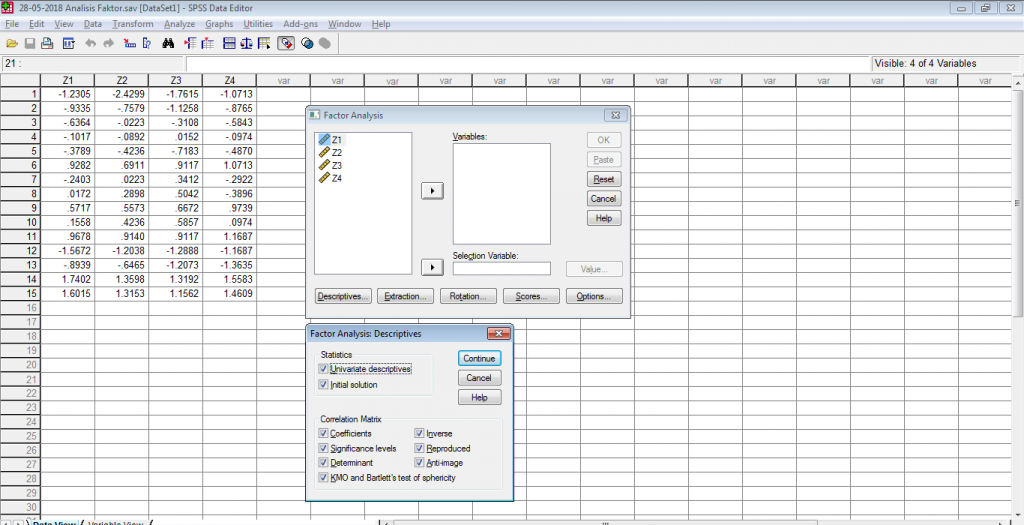
Klik pada menu Descriptive, pilih centang semua item yang ada pada menu Statistics dan Correlation Matrix untuk mendapatkan semua informasi yang diperlukan terkait pengujian analisis faktor pada data penelitian lalu klik Continue, seperti tampak pada gambar berikut.
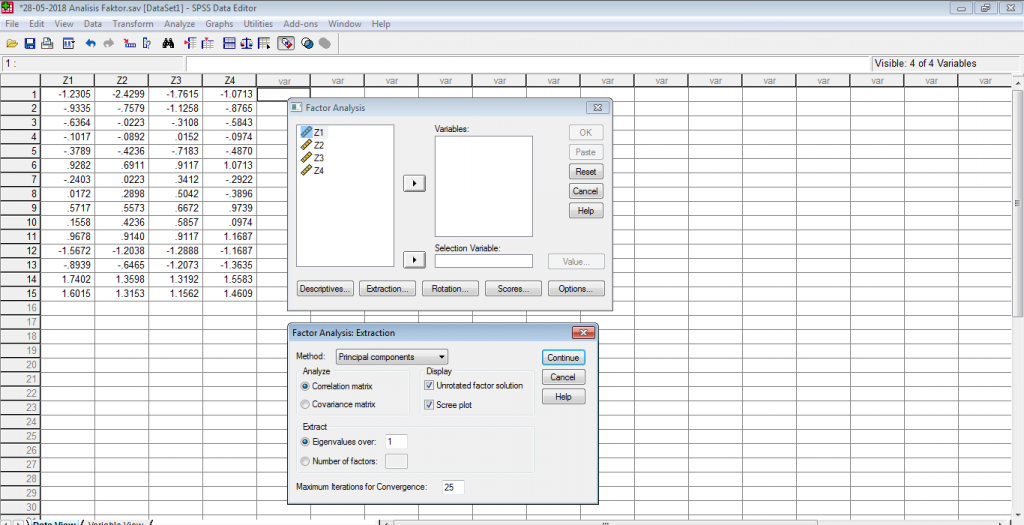
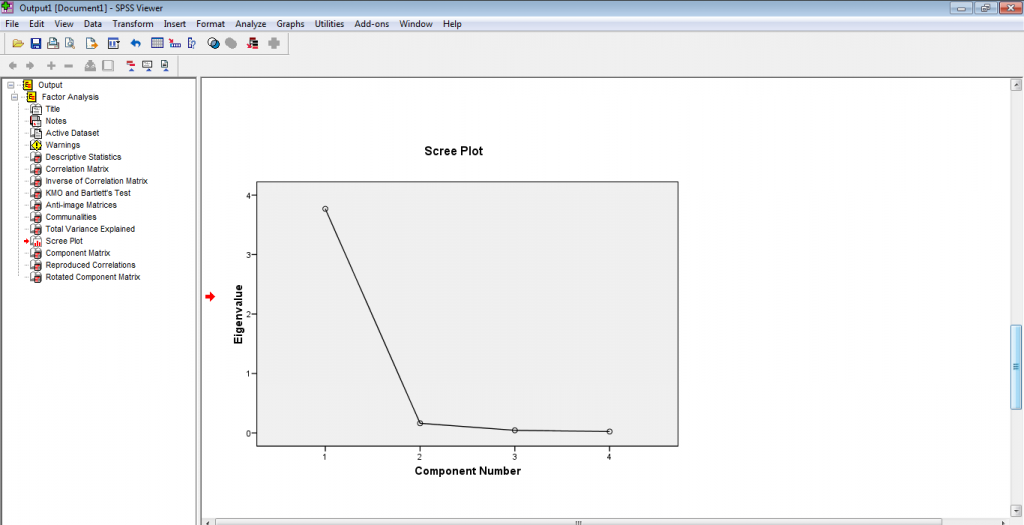
Klik pada menu Extraction, pilih Method pada Principal Components dan pada Display centang tambahan untuk menampilkan Scree Plot lalu klik Continue, seperti tampak pada gambar berikut.
Klik pada menu Rotation, pilih Method pada Varimax (disesuaikan dengan teori) dan pada Display centang pada semua menu lalu klik Continue, seperti tampak pada gambar berikut.
Klik pada menu Scores centang pada pilihan Save as variables dan pilih metode yang digunakan dalam proses menghasilkan nilai Score. Pemunculan nilai scores ini diperlukan jika hendak dilakukan analisis lanjutan terhadap data Scores yang dihasilkan.
Jika sudah yakin dengan berbagai pilihan perlakuan pada data dalam proses analisis, setelah semua variabel dimasukan ke dalam kolom Variables, lalu klik OK dan SPSS akan memproses data .
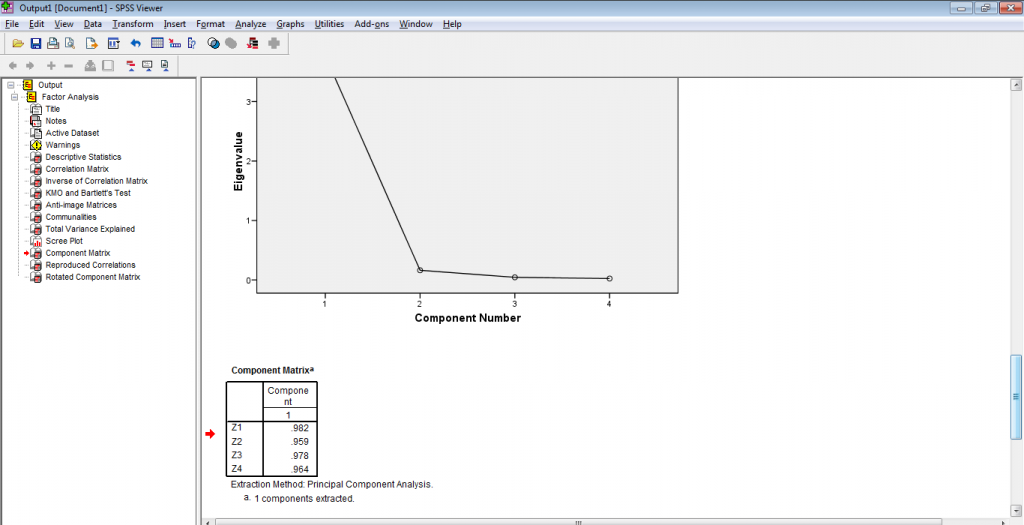
Hasil dari analisis faktor dengan menggunakan metode Principal Component yang diproses oleh SPSS seperti ditunjukkan pada gambar berikut. Penjelasan pada output SPSS disesuaikan dengan penjelasan pada artikel sebelumnya. Yang penting untuk diperhatikan adalah penentuan jumlah komponen utama dan besar keragaman yang dapat dijelaskan oleh komponen utama.
Ouput 1. Komponen Utama Terbentuk (Scree Plot)
Output 2. Nilai Loading Komponen Utama (Component Matrix)
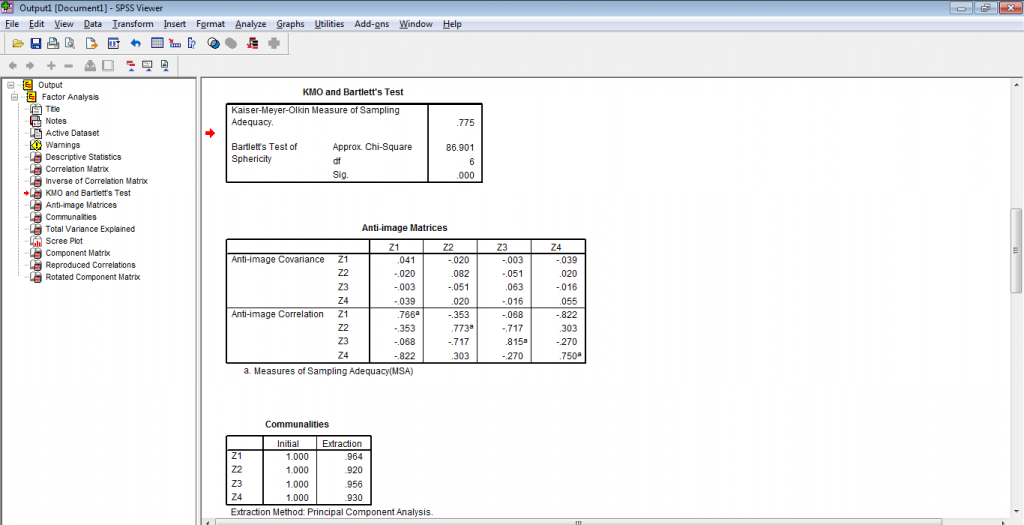
Output 3. Uji Kecukupan Data KMO dan Anti Image Matrix
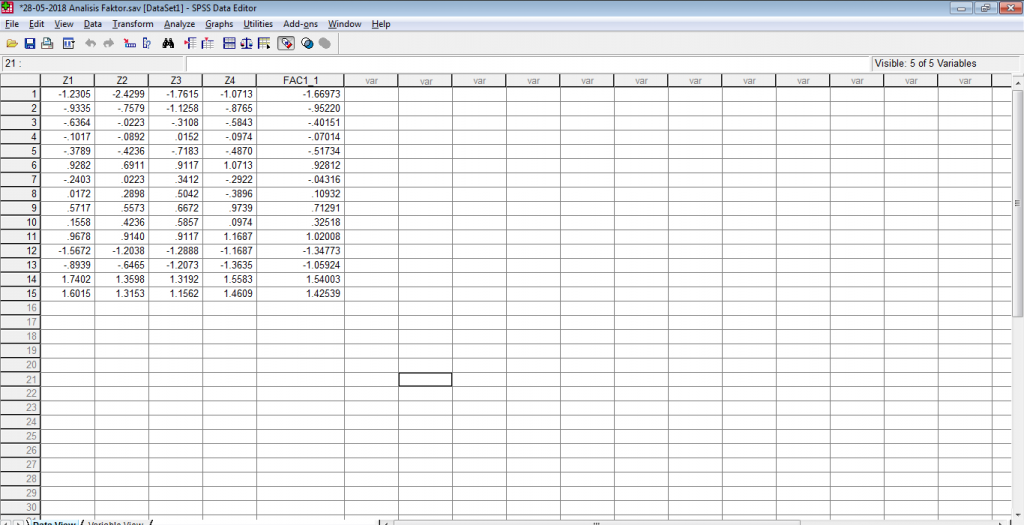
Selain bentuk output SPSS di atas, pada jendela Data View terdapat variabel baru yaitu skor dari faktor yang terbentuk. Nilai skor inilah yang nantinya menjadi data variabel baru yang dapat langsung diinterpretasikan maupun dilakukan pengujian lanjutan terhadap data variabel terbentuk.
Output 4. Score Faktor (Fac1)
Analisis Faktor Ekploratori seperti yang sudah kita paparkan pada artikel terkait dengan konsepsi dan fungsi metoda ini. Beberapa poin yang harus menjadi perhatian bagi peneliti adalah nilai pattern loading, nilai structure loading, nilai communalities dan nilai unique variance. Selain itu, peneliti pun dapat lebih memperhatikan pada ketiga ukuran kebaikan yang sudah dibahas pada artikel sebelumnya yaitu correlation matrix, anti image matrix dan Kaiser Meyer Olkin (KMO), agar faktor yang dihasilkan dapat diinterpretasikan secara maksimal dan merupakan hasil yang memenuhi kriteria uji. SEMANGAT MENCOBA!!!
Pada artikel sebelumnya kita sudah membahas secara konsepsi tentang analisis faktor eksploratori. Beberapa catatan yang kita anggap penting untuk kembali di review sebelum kita masuk dalam bahasan kriteria kebaikan dari analisis faktor eksploratori diantaranya nilai pattern loading, nilai structure loading, nilai communalities dan nilai unique variance yang dihasilkan analisis faktor pada data penelitian (Baca artikel : Analisis Faktor Eksploratori). Keempat komponen nilai pada faktor yang terbentuk tersebut bermanfaat dalam proses interpretasi dari faktor yang terbentuk baik untuk identifikasi penamaan maupun melihat kontribusi variabel pembentuk faktor. (Sekilas sama dengan interpretasi pada analisis komponen utama).
Hal lain yang selain nilai-nilai tersebut yang membedakannya dengan analisis komponen utama adalah adanya telaah lain yang khusus pada data yang akan digunakan dalam analisis faktor sehingga menjadikannya “rules of thumb” pada analisis faktor. Beberapa diantaranya adalah telaah pada matriks korelasi, pengujian pada nilai korelasi parsial (negative anti-image correlation) dan pengujian kecukupan sampel (Kaiser Meyer Olkin-KMO).
Pada kesempatan kali ini kita akan coba uraikan perspektif dari ketiga tools dalam melihat kebaikan data yang dugunakan dalam analisis faktor pada uraian berikut.
Matriks Korelasi
Analisis faktor mendasarkan proses perhitungannya adalah pada matriks korelasi. Sehingga indentifikasi pada matriks korelasi dalam analisis faktor dapat sangat membantu membentuk gambaran awal pada hasil pengelompokan variabel atas faktor yang terbentuk nantinya.
Suatu konsepsi sederhana yang dapat dibangun oleh peneliti bahwa korelasi yang tinggi diantara variabel menunjukkan bahwa variabel-variabel tersebut dapat dikelompokan dalam suatu set variabel yang homogen dimana variabel-variabel tersebut mengukur suatu faktor atau kontruk atau suatu dimensi tertentu (faktor yang dihasilkan dari analisis faktor). Sedangkan korelasi yang rendah diantara variabel menunjukkan bahwa variabel-variabel tersebut di kelompokan pada suatu set variabel yang heterogen dimana variabel-variabel tersebut mengukur suatu faktor atau kontruk atau suatu dimensi tertentu (faktor yang berbeda yang dihasilkan dari analisis faktor).
Jika konsepsi di atas berlaku maka hal ini menunjukkan bahwa faktor analisis merupakan suatu teknik analisis yang mencoba untuk mengidentifikasi kelompok atau mengelompokan variabel-variabel, dimana variabel-variabel dalam tiap grupnya merupakan indikator-indikator atas suatu faktor atau konstruk. Jika demikian kondisinya, maka matriks korelasi cocok untuk proses pem-faktor-an.
Noted : perlu diperhatikan bahwa ketiadaan korelasi yang erat antar variabel yang dilibatkan dalam perhitungan analisis faktor, dapat menghasilkan faktor yang banyak dan dapat menimbulkan kebingungan dalam mengidentifikasi faktor terbentuk (mis : penamaan) dikarenakan variabel-variabel yang mengelompok (misal) hanya terdiri atas 1 variabel/indikator.
Korelasi Parsial
Ukuran kedua yang dapat dijadikan patokan sekelompok variabel atau data cocok digunakan untuk analisis faktor adalah ukuran dari korelasi parsial. Korelasi parsial ini merujuk pada negative anti-image correlation yang mana nilainya harus sekecil mungkin agar matriks korelasi yang digunakan dalam baik atau cocok digunakan untuk analisis faktor.
Kaiser Meyer Olkin (KMO)
Salah satu ukuran lainnya yang dapat dijadikan patokan adalah menguji suatu ukuran dari Kaiser yaitu ukuran kecukupan sampel secara keseluruhan dan ukuran kecukupan sampel dari masing-masing variabel atau indikator. Kasier Meyer Olkin (KMO) adalah salah satu ukuran kecukupan sampel yang populer, dimana KMO menghasilkan suatu ukuran rata-rata yang dapat digunakan untuk menilai sejauh mana indikator-indikator atau variabel-variabel dari suatu kontruk atau faktor merupakan anggota bersama dari konstruk atau faktor tersebut. Oleh karenanya, KMO merupakan suatu ukuran kehomogenan dari variabel-variabel. Berikut disajikan panduan penggunaan ukuran KMO yang disarankan oleh Kaiser dab Rice (1974).
Tentunya nilai KMO yang tinggi yang diharapkan. Hal ini mensarankan bahwa ukuran overall KMO harus lebih besar dari 0.800, akan tetapi jika didapati nilai ukuran overall KMO di atas 0.600 masih dapat ditoleransi. Untuk dapat menigkatkan ukuran overall KMO yang tinggi biasanya dapat dilakukan dengan cara menghapus variabel atau indikator yang memiliki ukuran individual KMO yang bernilai rendah.
Selayaknya ketiga ukuran kebaikan data dalam aplikasinya pada analisis faktor dapat dicermati dan dipahami berdasarkan hasil perhitungan yang diterapkan pada data yang dimiliki oleh peneliti. Ketiga ukuran tersebut dalam pengaplikasiannya dapat dihasilkan dengan menggunakan software SPSS. Penting untuk kita review kembali bahwa selain nilai yang melekat pada faktor yang dihasilkan dari analisis faktor (nilai pattern loading, nilai structure loading, nilai communalities dan nilai unique variance), peneliti pun dapat lebih memperhatikan pada ketiga ukuran kebaikan yang sudah dibahas, agar faktor yang dihasilkan dapat diinterpretasikan secara maksimal dan merupakan hasil yang memenuhi kriteria uji.
Pada kesempatan yang lain akan kita coba uraikan pengaplikasian metode analisis faktor eksploratori dengan menggunakan SPSS untuk memperlihatkan penerapan konsepsi secara teoritis dengan hasil secara aplikasi. SEMANGAT MEMAHAMI!!!
Sumber : Subhash Sharma, Applied Multivariate Technique
Pada kesempatan yang lalu kita sudah mengupas tuntas salah satu metode analisis pada rumpun analisis multivariat, yaitu analisis komponen utama (AKU) atau principal component analysis (PCA). Jika kita ulas singkat apa itu AKU atau PCA, yaitu suatu metode dalam rumpun analisis multivariat yang berguna dalam meringkas atau mereduksi data dalam artian meringkas variabel-varibel (yang banyak) yang digunakan dalam analisis menjadi hanya beberapa buah komponen utama/faktor saja, dimana komponen utama (PC) yang terbentuk merupakan kombinasi dari variabel-variabel awal, (misal : 2 atau 3 buah) yang dapat menjelaskan sebagian besar variasi pada data atau variabel awal tersebut (min ; 80% s.d 90%).
Nah, pada kesempatan kali ini kita akan sedikit mengupas salah satu metode lainnya yang merupakan rumpun analisis multivariat, yang memiliki kedekatan atau kemiripan dengan analisis komponen utama (AKU) akan tetapi memiliki fungsi dan perbedaan yang mendasar baik secara formula maupun kegunaanya. Jika pada pembahasan awal kita juga sudah membahas tentang analisis faktor komfirmatori (CFA) yang melandaskan konsepnya pada konsep observed dan laten variabel (pendefinisian variabel berdasarkan landasan teoritik yang jelas dan umum – korelasi antar variabel indikator sudah terbukti dalam membentuk suatu variabel laten), sedangkan pada analisis faktor eksploratori belum melandasakan pada konsepsi tersebut pada awal pembentukannya (observed dan laten variabel) dan lebih dekat landasannya pada konsepsi analisis komponen utama (AKU) yaitu pendefinisian variabel-variabel atas faktor yang terbentuk (korelasi antar variabel indikator belum terbukti secara teoritik dalam membentuk suatu variabel laten).
Lebih lanjut kita akan uraikan secara substansial pada paparan selanjutnya.
Analisis Faktor Eksploratori
Dalam studi ketergantungan semua variabel memiliki peranan yang sama, oleh karena itu peneliti harus memperhatikan struktur hubungan secara keseluruhan diantara variabel-variabel yang mencirikan objek-objek pengamatan. Pada awalnya teknik analisis faktor dikembangkan dalam bidang psikometrik atas usaha dari Karl Pearson, Charles Spearman, dan lainnya untuk mendefinisikan dan mengukur intelegensia seseorang. Tujuan utama dari analisis faktor adalah menjelaskan hubungan diantara banyak variabel dalam bentuk beberapa faktor. Faktor-faktor itu merupakan besaran acak yang tidak dapat diamati (diukur) secara langsung.
Misal : Faktor proses industrialisasi di berbagai daerah tidak dapat diamati secara langsung, tetapi diukur melalui berbagai variabel ukuran industrialisasi, seperti kontribusi industri manufaktur dalam pembentukan produk domestik regional bruto (PDRB), persentase kerja sektor industri dan lain-lain.
Analisis faktor dapat pula dipandang sebagai perluasan dari analisis komponen utama. Keduanya, merupakan teknik analisis yang menjelaskan struktur hubungan di antara banyak variabel dalam sistem konkret.
Konsep Dasar Analisis Faktor Eksploratori
Model analisis faktor mempostulatkan bahwa vektor acak X tergantung secara linear pada beberapa variabel acak yang tidak teramati (unobservable random variabel), F1, F2, . . . , Fm, yang disebut faktor-faktor bersama (common factors) dan p sumber keragaman tambahan e1, e2, . . . , ep yang disebut sebagai galat (error) atau kadang-kadang disebut juga sebagai faktor-faktor spesifik (unique variance).
Di mana :
Fj (j = 1, 2, . . , m) merupakan faktor bersama ke-j
Cij (i = 1, 2, . . , p dan j = 1, 2, . . , m) merupakan paramter yang mereflesikan pentingnya faktor ke-j dalam komposisi dari respon ke-i, dalam analisis faktor disebut sebagai bobot (loading) dari respon ke-i pada faktor bersama ke-j.
ϵi (i = 1, 2, . . , p) merupakan galat dari respon ke-i dalam analisis faktor disebut sebagai faktor spesifik ke-i yang bersifat acak.
Struktur peragam untuk model analisis faktor dinyatakan dalam persamaan sebagai berikut,
Dari persamaan di atas tampak bahwa ragam dari variabel respon Xi diterangkan oleh dua komponen yaitu komponen h dan ψ. Komponen h disebut sebagai komunalitas yang menunjukkan proporsi ragam dari variabel respon X yang diterangkan oleh m faktor bersama, sedangkan ψ merupakan proporsi ragam dari variabel respon X yang disebabkan oleh faktor spesifik atau galat (error) dan disebut ragam spesifik (unique variance).
Pada dasarnya terdapat dua metode pendugaan parameter dalam model analisis faktor yaitu metode komponen utama (principal component method) dan metode kemungkinan maksimum (maximum likelihood method). Dalam kebanyakan analisis terapan, model analisis faktor diduga berdasarkan metode komponen utama, demikian pula dalam kebanyakan paket aplikasi komputer proses komputasi didasarkan pada metode komponen utama.
Hal lain dalam analisis faktor yang perlu diperhatikan adalah rotasi faktor (factor rotation). Dalam situasi tertentu apabila m buah faktor bersama yang dilibatkan dalam analisis cukup banyak, katakanlah m > 2, maka terkadang didapati kesulitan dalam menginterpretasikan faktor-faktor tersebut karena adanya tunpang tindih variabel-variabel X yang diterangkan oleh m buah faktor bersama tersebut. Untuk mengatasi hal tersebut, maka dilakukann rotasi yang dikenal dengan sebagai rotasi faktor. Rotasi faktor tidak lain merupakan transformasi orthogonal dari faktor-faktor. Jika C adalah matriks dugaan untuk bobot faktor (faktor loading), maka rotasi faktor akan menghasilkan matriks bobot “rotasi” faktor C*. Salah satu bentuk transformasi yang dapat dipergunakan adalah berdasarkan kriteria rotasi varimax yang diperkenalkan oleh Kaiser (1958). Kriteria varimax sering disebut juga sebagai kriteria varimax normal. Prosedur varimax adalah memilih matriks transformasi ortoghonal yang memaksimalkan matriks bobot C* pada tiap faktor yang terbentuk.
Dan berbeda dengan analisis komponen utama yang relatif tidak terlalu banyak pembahasan pada kriteria data yang digunakan dalam analisis, maka pada analisis faktor terdapat beberapa kriteria yang harus dipenuhi pada data untuk memastikan bahwa metode yang diterapkan pada data memaksimalkan faktor yang dihasilkan atas variabel X. Beberapa kriteria yang perlu diperhatikan oleh peneliti diataranya matriks korelasi, korelasi parsial (negative anti-image correlation) dan ukuran kecukupan sampel (Kaiser Meyer Olkin-KMO). Pada kesempatan yang lain kita akan coba jelaskan penjelasan dan fungsi dari kriteria-kriteria tersebut secara spesifik.
…
Setelah kita membahas konsep analisis faktor sekira kita dapatkan kejelasan dan dapat membedakan dengan metode yang telah dibahas pada artikel sebelumnya, yaitu analisis komponen utama. Meskipun analisis faktor dapat dibangun dari konsepsi analisis komponen utama (secara metode), akan tetapi yang perlu diperhatikan adalah perbedaan penggunaan kedua metode tersebut secara fungsi pada tujuan penelitian dilakukannya penerapan kedua metode tersebut pada data penelitian. Ini penting karena akan mempengaruhi interpretasi pada hasil perhitungan yang dilakukan pada data. SEMANGAT MEMAHAMI!!!
Pada dua artikel terdahulu kita sudah sedikit banyak memaparkan metode dalam menghasilkan model regresi data deret waktu, yaitu rumpun metode penghalusan eksponensial (eksponensial sederhana, Holt, Winters dan Holt–Winters) dan metode Box-Jenkins. Pastinya para pembaca menemukan kerumitan dalam memahami metode-metode yang sudah paparkan sebelumnya, karena secara naratif penuh dengan konsepsi matematis yang cukup kompleks. Setidaknya pada tahap awal, para pembaca dapat lebih menekankan pemahaman pada ciri tiap metode dan tahapan dalam melakukan analisis data deret waktu, hal ini dapat mempermudah dalam penerapan pada data dan aplikasi pada software pembantu. Pada tahap lanjut para pembaca dapat memfokuskan pada pembentukan model matematis yang diperlukan dalam peramalan dari hasil output software pembantu yang digunakan.
Pada kesempatan kali ini kita akan coba uraikan satu metode lain dari analisis data deret waktu yang mungkin diperlukan bagi para peneliti dan sesuai dengan kondisi data yang dimilikinya, metode tersebut adalah metode autoregresi stepwise.
Sekali lagi, diperlukan pengalaman dan sensitifitas peneliti atau data master dalam menentukan dan memutuskan metode yang paling tepat bagi data deret waktu yang dimiliki. Assistansi maupun konseling yang dilakukan bersama expertise maupun praktisi sangat disarankan untuk mengkonfirmasikan self judgement terhadap penentuan metode dan interpretasi dari hasil olah data regresi deret waktu.
Metode Autoregresi Stepwise
Metode ini dikenalkan oleh C.W. Granger dan P. Newbold sekitar tahun 1977, yang merupakan bagian (subset) dari metode Box-Jenkins, dengan konsepsi yang lebih sederhana. Pada metode Box-Jenkins, model regresi deret waktu yang digunakan untuk peramalan adalah ARIMA (p,q,k), sedangkan metode ini didasarkan pada konsepsi bahwa jika data berautokorelasi, maka model hubungan fungsionalnya adalah AR (k), dengan alasan diantaranya adalah
Model AR (k) adalah model dasar dari regresi deret waktu
Membangun model AR (k) yang cocok untuk peramalan lebih mudah dari model MA (p) atau ARMA (k,p)
Sedangkan konsepsi perhitungan dari metode autoregresi stepwise adalah sebagai berikut
Lakukan proses menstasionerkan data dan seperti sudah dikemukakan jika trendnya linear maka proses diferensi orde 1 sudah cukup, tetapi jika tidak linear maka lakukan transformasi linearitas selanjutnya proses diferensi orde 1 untuk hasil transformasi
Tentukan Lag autokorelasi minimum yang mungkin, misal sama dengan M. Granger dan Newbold menyarankan ambil M = 13 jika data kuartal dan M = 25 jika data bulanan.
Bangun model regresi deret waktu dengan persamaan berikut,
Dimana: Wt = Xt – Xt-1; Xt merupakan data deret waktu dengan trend linear, γs(1) merupakan koefisien autoregresi stepwise orde 1 dan et(1) merupakan kekeliruan model autoregresi stepwise orde 1.
Lakukan penaksiran parameter secara bertahap untuk setiap S = 1, 2, . . , M dan hitung nilai-nilai ramalannya.
Proses penaksiran dihentikan jika jumlah kuadrat residu pada langkah ke-j sudah cukup kecil dari langkah sebelumnya dan model yang dihasilkan dapat digunakan sebagai model ramalan.
Pemilihan Metode
Banyak faktor yang harus dijadikan bahan pertimbangan untuk melakukan suatu proses peramalan data deret waktu, beberapa diantaranya,
Tujuan melakukan peramalan
Derajat keteparan yang diinginkan
Ketersediaan waktu, biaya, sumber daya manusia dan fasilitas
Tidak ada aturan yang mengikat untuk memutuskan penggunaan salah satu metode peramalan berdasarkann pertimbangan yang telah dibuat, sehingga jika ada beberapa metode yang dapat digunakan maka pilihan harus pada metode yang memiliki efisiensi dengan tingkat kekeliruan yang paling kecil.
Dalam ilmu statistika peramalan didasarkan pada sebuah model regresi, jika sebuah model ramalan dipilih maka harus dipertimbangkan adalah
Keberartian dari penaksir koefisien regresi yang dapat dilakukan berdasarkan analisis varians
Kekeliruan baku model yang dapat ditelaah berdasarkan analisis residual
Dipenuhi tidaknya asumsi yang dapat dilakukan berdasarkan sebuah pengujian hipotesis
Lead time maksimum yang harus sesuai dengan ukuran sampel.
Sekalipun kompleks dan cenderung rumit dalam proses pembentukan model regresi data deret waktu, berdasar pada pemahaman yang sempurna akan basic informasi pada data deret waktu yang dimiliki, akan mempermudah peneliti atau data master dalam proses pengaplikasian data pada software support yang dipilihnya, baik itu SPSS, SAS, MINITAB dan yang lainnya, berdasarkan pemilihan metode yang tepat pula.
Seperti pembahasan yang sudah kita paparkan pada artikel sebelumnya, bahwa model regresi data deret waktu berbeda dengan metode yang digunakan dalam menghasilkan data deret waktu. Pada pembahasan artikel sebelumnya sedikit kita bahas konsepsi metode dalam rumpun penghalusan exponensial (exponential smoothing) yang terdiri dari metode eksponensial sederhana, Holt, Winters dan Holt-Winters. Prinsip pada metode-metode tersebut adalah indentifikasi pada pola data deret waktu (trend dan pola musiman) dan pembobotan pada pembentukan modelnya. Selain itu, metode-metode tersebut relatif tidak begitu fokus pada pemenuhan kebagusan data deret waktu dalam pembentukan modelnya. Box-Jenkins!
Pada kesempatan kali ini kita akan membahas metode lainnya yang sangat memperhatikan faktor kebagusan data deret waktu dalam membentuk modelnya. Metode yang dimaksud adalah metode Box-Jenkins. Oleh karenanya sebelum pada pemahaman terkait dengan spesifik konten metode didalamnya, ada baiknya para pembaca memahami konsep dasar dari data deret waktu yang telah kita tuliskan pada artikel-artikel sebelumnya, baik itu terkait dengan autokorelasi, stasioneritas data, transformasi data hingga ke model-model regresi data deret waktu. Pemahaman tersebut setidaknya dapat memudahkan memandu para pembaca dalam memahami setiap tahapan yang akan dijelasakan pada metode Box-Jenkins.
Sekali lagi, diperlukan pengalaman dan sensitifitas peneliti atau data master dalam menentukan dan memutuskan metode yang paling tepat bagi data deret waktu yang dimiliki. Assistansi maupun konseling yang dilakukan bersama expertise maupun praktisi sangat disarankan untuk mengkonfirmasikan self judgement terhadap penentuan metode dan interpretasi dari hasil olah data regresi deret waktu.
Metode Box-Jenkins
Proses peramalan dengan metode ini dikenalkan dan dikembangkan oleh G.E.P Box dan G.M. Jenkins pada tahun 1960-an. Peramalan dengan metode Box-Jenkins pada umumnya akan memberikan hasil yang lebih baik dari metode-metode peramalan lain, sebab metode ini tidak mengabaikan kaidah-kaidah pada data deret waktu, tetapi proses perhitungannya cukup kompleks jika dibandingkan dengan metode peramalan yang lainnya. Berdasarkan pengalaman jika diinginkan hasil yang baik, ukuran sampel untuk digunakan dalam peramalan dengan metode Box-Jenkins paling kecil 50 dan lebih baik lagi jika lebih dari 100.
Peramalan dengan metode Box-Jenkins didasarkan pada model regresi deret waktu stasioner tanpa komponen musiman, sehingga jika yang dianalisis data bulanan maka perlu ditelaah keberadaan komponen musimannya, sebab jika ada, komponen ini harus dieliminasi melalui proses diferensiasi. Langkah-langkah penting yang harus dilakukan jika akan melakukan peramalan dengan metode Box-Jenkins adalah sebagai berikut,
Petakan data atas waktu dan telaah mengenai bentuk trend, kestabilan varians dan keberadaan komponen musiman, untuk menentukan bentuk transformasi kelinearnan trend, kestabilan varians dan eliminasi komponen musiman (jika ada).
Hitung ACF dan PACF dan gambarkan korelogramnya untuk data asli dan data hasil transformasi untuk menelaah orde diferensi dan autoregresi yang akan diambil.
Bagun model-model ARIMA (k,q,p) yang kemungkinan cocok untuk data yang dimiliki
Lakukan penaksiran parameter untuk setiap model yang dibangun
Lakukan analisis varians atau analisis residual untuk menentukan model ramalan yang akan digunakan. Model ramalan yang digunakan adalah model yang signifikan dengan kekeliruan baku model yang paling kecil.
Jika diperlukan maka deskripsikan model-model alternatifnya.
Peramalan dengan metode Box-Jenkins data harus stasioner dan tidak memiliki komponen musiman. Sehingga tahap pertama dari proses peramalan dengan metode ini adalah proses diferensi untuk menstasionerkan data dan menghilangkan komponen musiman (jika ada). Jika trend linear dan tidak ada komponen musiman maka diferensi orde-1 biasanya sudah cukuup untuk menstasionerkan data. Tetapi jika trend linear dan ada komponen musiman dengan periode p ≤ 12 (pada umunya p = 12, tetapi untuk beberapa kasus, misalnya dalam bidang klimatologi bisa saja p < 12 sehingga dalam satu tahun komponen musiman lebih dari satu), maka orde diferensinya p jika musiman aditif dan 2/p jika multifikatif.
Dalam prakteknya proses diferensi dengan orde paling besar sama dengan p sudah cukup untuk menghilangkan komponen musiman, baik yang aditif atau multifikatif, sebab jika orde diferensi terlalu tinggi akan menyebabkan banyak data hilang (secara matematis jika orde diferensi p maka data hilang akan sebanyak p+1 buah). Dalam hal ini trend tidak linear seperti sudah dikemukakan sebelum melakukan proses diferensi harus dilakukan proses linearitas trend.
Jika model yang cocok sudah diperoleh berdasarkan sampel berukuran n, maka selanjutnya lakukan ramalan untuk k langkah ke depan (sebaiknya k < ¼ n). Box-Jenkins mengemukakan model ramalan cukup baik untuk digunakan jika nilai residu, yaitu selisih antara nilai pengamatan dengan nilai ramalannya cukup kecil, sehingga setiap nilai ramalan yang diperoleh perlu ditelaah kewajarannya berdasarkan nilai residu tersebut.
Metode Box-Jenkins Dengan Trend dan Musiman
Sudah dikemukakan sebelumnya, model regresi deret waktu yang digunakan sebagai model ramalan dengan metode Box-Jenkins adalah model ARIMA (k,p,q) tanpa komponen trend dan musiman, sehingga jika ada maka komponen-komponen tersebut harus dieliminasi dulu melalui proses diferensi dan selanjutnya model ARIMA (k,q.p) dibangun berdasarkan data yang telah dieliminasi. Konsepsi ini secara statistis dapat digeneralisasikan dalam model ARIMA (k,q,p) trend-musiman, yang biasa dinamakan model Box-Jenkins (K,k,P,p) dengan persamaan sebagai berikut,
Dengan ΓK(B), lk(B12), ΨP(B), ψp(B12), masing-masing polinom atas operator backshift B dengan orde masing-masing k (orde AR), K (orde AR musiman), p ( orde MA) dan P (orde MA musiman). at merupakan “kekeliruan Box-Jenkins yang merupakan variabel acak tidak terukur dengan rata-rata nol dan varians konstan. Dan Wt merupakan variabel yang dibangun dari variabel Xt berdasarkan proses diferensi untuk mengeliminasi komponen trend dan musiman,
Dengan d merupakan orde diferensi untuk mengeliminasi komponen trend dan D untuk komponen musiman. Sebagai misal jika d = D = 1 dan K = p = 1 serta k = P = 0 maka model Box-Jenkins-nya adalah sebagai berikut,
Maka
Jika ditelaah, maka persamaan di atas merupakan gabungan model ARMA (1,1) dengan proses diferensi orde 1, sehingga persamaan di atas selanjutnya dinamakan model trend-musiman ARIMA (1,1,1) atau model Box-Jenkins (1,0,0,1).
Walaupun metode Box-Jenkins dan Holt-Winters adalah proses peramalan untuk data yang memiliki komponen trend dan musiman, tetapi ada perbedaan yang mencolok antara keduanya. Metode Holt-Winters adalah proses peramalan berdasarkan analisi “keluarga model regresi sederhana”, sedangkan metode Box-Jenkins berdasarkan analisis “pemilihan model trend-musiman ARIMA”, dengan proses yang lebih kompleks daripada metode Holt-Winters.
Pada akhirnya, sekalipun kompleks dan cenderung rumit dalam proses pembentukan model regresi data deret waktu, berdasar pada pemahaman yang sempurna akan informasi dasar pada data deret waktu yang dimiliki, akan mempermudah peneliti atau data master dalam proses pengaplikasian data pada software support yang dipilihnya, baik itu SPSS, SAS, MINITAB dan yang lainnya, berdasarkan pemilihan metode yang tepat pula.
Pada kesempatan yang lalu dalam beberapa artikel kita sudah banyak membahas konsepsi tentang data deret waktu dan model regresi deret waktu. Perlakuan terhadap data deret waktu lebih kompleks dibandingkan kita memperlakukan data cross sectional dalam pembentukan model regresi. Perlu effort lebih dari peneliti atau data master dalam memperlakukan data deret waktu, mulai dari sensitifitas pada visual data maupun sensitifitas dalam penentuan metode matematis yang tepat dalam men-treatment data yang dimilikinya. Exponential Smoothing!
Pemaparan pada artikel sebelumnya kita banyak membahas terkait dengan bagaimana bentuk ideal dari data deret waktu yang dapat membantu peneliti dalam memperoleh nilai ramalan yang robust berdasarkan model regresi data deret waktu yang terbentuk berdasarkan metode yang digunakannya, dan umumnya dengan urutan penjelasan sebelumnya merujuk kepada metode Box-Jenkins. Sedangkan metode lainnya yang relatif tidak terlalu memperhatikan secara detail urutan kebagusan data deret waktu diantaranya adalah metode Exponential Sederhana, Holt, Winters dan Holt-Winters.
Nah, pada beberapa artikel kedepan kita akan coba menguraikan secara singkat secara pengertiaan dan konsepsi beberapa metode yang dapat digunakan pada data deret waktu dalam membentuk suatu model regresi data deret waktu. Beberapa metode yang akan kita paparkan diantaranya Exponential Sedehana, Holt, Winters, Holt-Winters, Box-Jenkins dan Autoregresi Stepwise. Sekali lagi, diperlukan pengalaman dan sensitifitas peneliti atau data master dalam menentukan dan memutuskan metode yang paling tepat bagi data deret waktu yang dimiliki. Assistansi maupun konseling yang dilakukan bersama expertise maupun praktisi sangat disarankan untuk mengkonfirmasikan self judgement terhadap penentuan metode dan interpretasi dari hasil olah data regresi deret waktu.
Metode Exponential Sederhana
Metode penghalusan eksponensial (exponential smoothing) merupakan metode peramalan univariat, yang dikenalkan oleh C.C Holt pada sekitar tahun 1958. Metode penghalusan sederhana digunakan jika data tidak memiliki komponen musiman dan trend. Misalkan dimiliki sampel data deret waktu x1, x2, . . . ,xn, yang tidak memiliki komponen trend dan musiman, dan diinginkan nilai ramalan untuk k waktu ke depan (lead time), dimana k < n. Jika peramalan dilakukan dengan metode penghalusan sederhana, maka proses dilakukan secara bertahap dimulai dengan lead time 1, berdasarkan sebuah kombinasi linear pembobotan sampai dengan lead time ke-k,
Dengan Ci adalah pembobot, 0 < Ci < 1, dan Ʃ Ci = 1. Untuk menentukan nilai-nilai pembobot, salah satu cara adalah dengan menggunakan persamaan di bahwa ini dan nilai α dihitung dengan metode rekursif.
Note : Lead time ke k sama dengan “waktu mendatang ke k”
Metode Holt
Peramalan dengan penghalusan eksponen sederhana dilakukan jika data tidak mengandung komponen trend dan musiman, sedangkan jika mengandung komponen trend tetapi tidak mengandung komponen musiman, maka harus digunakan metode Holt, yaitu metode penghalusan eksponensial dengan dua kali pembobotan.
Metode ini pada awalnya digunakan untuk data bulanan yang tidak memiliki komponen musiman dan dalam perkembangnya dapat digunakan untuk data tahunan dengan proses analisisnya mengadopsi proses untuk data bulanan. Misalkan dimiliki sampel data deret waktu x1, x2, . . . ,xn, yang tidak memiliki komponen musiman. Jika dideskripsikan, mt adalah taksiran rata-rata pada bulan yang sama (current mean) untuk bulan ke t, dimana t = 1, 2, … , 12. Tt adalah taksiran pola trend pada bulan ke t, dimana t = 1, 2, … , 12. Maka formulasi pembobotannya adalah sebagai berikut,
Dimana 0 < α dan γ < 1 yang merupakan konstantan real dan xt merupakan pengamatan terakhir bulan ke-t. Peramalan nilai data waktu ke-t dengan lead time ke-k dihitung dengan persamaan,
Note : Lead time ke k sama dengan “waktu mendatang ke k”
Metode Winters
Metode ini merupakan penghalusan eksponensial juga dan digunakan jika data memiliki komponen musiman, tetapi tidak memiliki komponen trend. Metode ini digunakan juga jika data adalah data bulanan, sebab musiman hanya dideskripsikan pada data bulanan. Secara umum, yang dimaksud dengan musiman adalah komponen siklis dengan periode 12 bulan.
Konsepsi perhitungan metode Winters indentik dengan metode Holt, yaitu penghalusan eksponensial dengan dua kali pembobotan. Misalkan dimiliki sampel data deret waktu x1, x2, . . . ,xn, yang memiliki komponen musiman, tetapi tidak memiliki komponen trend. Selanjutnya jika didefinisikan mt adalah taksiran rata-rata pada bulan yang sama untuk bulan ke-t, t = 1, 2, .. , 12. Dan st adalah faktor musiman pada bulan ke-t, t = 1, 2, .. , 12 serta komponen musimannya multiplikatip dengan persamaan,
Maka formulasi pembobotannya adalah sebagai berikut,
Dan nilai ramalan untuk lead time ke-h, dihitung dengan formulasi,
Sedangkan jika komponen musimannya aditif dengan persamaan,
Dengan formulasi pembobotannya adalah sebagai berikut,
Dan nilai ramalan untuk lead time ke-h, diitung dengan formulasi,
Pada formulasi pembobotan, xt pengamatan terakhir pada bulan ke-t, α dan δ merupakan konstanta real, dimana 0 < α dan δ < 1. Sedangkan lead time h = 1, 2, .., 12.
Metode Holt-Winter
Metode peramalan Holt-Winter merupakan gabungan dari metode Holt dan metode Winters, digunakan untuk peramalan jika data memiliki komponen trend dan musiman. Metode ini juga merupakan penghalusan eksponensial dengan tiga kali pembobotan.
Misalkan dimiliki sampel data deret waktu x1, x2, . . . ,xn, yang memiliki komponen trend dan musiman. Selanjutnya jika didefinisikan mt adalah taksiran rata-rata pada bulan yang sama untuk bulan ke-t. st adalah faktor musiman pada bulan ke-t. dan Tt adalah pola trend pada bulan ke-t. Maka formulasi pembobotan Holt-Winters jika komponen musimannya aditif adalah
Dan jika komponen musimannya multifikatif,
Proses perhitungan untuk α, γ dan δ sama seperti pada metode Holt.
Sekalipun kompleks dan cendeung rumit dalam proses pembentukan model regresi data deret waktu, berdasar pada pemahaman yang sempurna akan informasi dasar pada data deret waktu yang dimiliki, akan mempermudah peneliti atau data master dalam proses pengaplikasian data pada software support yang dipilihnya, baik itu SPSS, SAS, MINITAB dan yang lainnya, berdasarkan pemilihan metode yang tepat pula.
Pada kesempatan yang lalu kita sudah membahas konsep perluasan dari analisis regresi dengan mempertimbangkan ketergantungan pada aspek kewilayahan (spasial). Pada dasarnya penggunaan regresi spasial harus dipastikan bahwa ketergantungan atau keberagaman dari aspek wilayah signifikan pada model regresi sehingga penggunaan regresi spasial pada data merupakan langkah yang tepat, akan tetapi jika hasil pengujian tidak signifikan maka regresi biasa merupakan langkah tepat yang sederhana. Selain itu, pembahasan pengaplikasian data pada software GWR 4 dapat membantu peneliti atau data master dalam memahami tahapan dalam menghasilkan model regresi yang terboboti oleh kewilayahan (spasial).
Pada kesempatan kali ini akan sedikit diuraikan pemahaman terhadap salah satu intrumen yang ada pada regresi spasial yang sangat menentukan dalam mengukur baik atau tidaknya model regresi spasial yang dihasilkan oleh data yaitu metode yang erat kaitannya dengan bandwidth yang dihasilkan untuk model. Pembahasan kali ini ada kaitannya juga dengan pertanyaan pembaca, yang hendak memahami secara konsepsi apa itu dan teknik penentuan bandwidth.
Definisi Bandwidth
Secara teoritis, bandwidth merupakan lingkaran dengan radius (b) dari titik pusat lokasi yang digunakan sebgai dasar penentuan bobot setiap pengamatan terhadap model regresi pada lokasi tersebut. Untuk pengamatan-pengamatan yang dekat dengan lokasi i maka akan lebih berpengaruh dalam membentuk parameter model lokasi ke-i. Karena itu pengamatan-pengamatan yang terletak di dalam radius (b) masih dianggap berpengaruh terhadap model pada lokasi tersebut, sehingga akan diberi bobot yang akan bergantung pada fungsi yang digunakan.
Metode pemilihan bandwidth sangat penting digunakan untuk pendugaan fungsi kernel yang tepat. Nilai bandwidth yang sangat kecil akan mengakibatkan varians membesar. Hal tersebut dapat disebabkan karena jika nilai bandwidth sangat kecil maka akan sedikit pengamatan yang berbeda pada radius (b). Namun ketika nilai bandwidth yang sangat besar akan mengakibatkan varians mengecil. Sehingga untuk menghindari varians yang tidak homogen akibat nilai pendugaan koefisien parameter yang meningkat, maka diperlukan suatu cara untuk memilih bandwidth yang tepat.
Menurut Fortheringham, dkk (2002) beberapa metode pilihan untuk pemilihan bandwidth optimum adalah sebagai berikut : 1) Cross Validation; 2) Akaike Information Criterion (AIC); 3) Generalized Cross Validation (GCV) dan 4) Bayesian Information Criterion (BIC).
Definisi Fungsi Likelihood
Karena dalam beberapa metode yang digunakan untuk menentukan bandwidth terdapat istilah likelihood, yang merupakan istilah matematik statistik, ada baiknya kita coba sampaikan sedikit pengertian terkait dengan likelihood atau fungsi likelihood yang merujuk pada definisi atau konsepsi yang diuraikan pada literatur rujukan.
Ide umum yang melatarbelakangi metode maksimum likelihood adalah sebagai berikut. Misalkan f(x,θ) merupakan fungsi kepadatan (density function) dari variabel random X dan misalkan θ merupakan parameter fungsi kepadatan. Kalau kita mengamati suatu sampel random X1, X2, . . , XN, maka penaksiran maksimum likelihood dari θ adalah nilai θ yang mempunyai probabilitas terbesar untuk menghasilkan sampel yang diamati. Dengan perkataan lain, taksiran maksimum likelihood dari θ adalah yang memaksimumkan fungsi kepadatan (density function). Note : fungsi kepadatan dapat diperjelas dengan pengdekatan distribusi peluang (jenis distribusi peluang yang sesuai dengan data).
Secara prinsipil pemahaman atas fungsi likelihood yang didapat dari literatur adalah sebagai berikut.
In frequentist inference, a likelihood function (often simply the likelihood) is a function of the parameters of a statistical model, given specific observed data. Likelihood functions play a key role in frequentist inference, especially methods of estimating a parameter from a set of statistics. In informal contexts, “likelihood” is often used as a synonym for “probability”. In mathematical statistics, the two terms have different meanings. Probability in this technical context describes the plausibility of a future outcome, given a model parameter value, without reference to any observed data. Likelihood describes the plausibility of a model parameter value, given specific observed data.
Cross Validation
Cross validation adalah salah satu teknik dalam mendapatkan nilai bandwidth yang sangat berguna dalam mendapatkan nilai pembobotan yang akan digunakan dalam proses perhitungan model regresi spasial. Jika dilihat dari perumusan yang digunakan untuk mendapatkan nilai bandwidth, CV, memiliki pola perumusan yang paling sederhana, seperti tampak pada perumusan CV berikut,
dengan y taksiran (y topi) adalah nilai penaksir yi dimana pengamatan di lokasi (ui,vj) dihilangkan dari proses estimasi. Untuk mendapatkan nilai radius (b) yang optimal maka diperoleh dari radius (b) yang menghasilkan nilai CV yang minimum.
Jika kita merujuk pada pemahaman dasar tentang cross validasi dan keluar telebih dahulu dari konsep bandwidth maka cross validasi dapat dimaknai sesuai dengan definisi dari literatur sebagai berikut.
“Cross-validation, sometimes called rotation estimation, is a model validation technique for assessing how the results of a statistical analysis will generalize to an independent data set. It is mainly used in settings where the goal is prediction, and one wants to estimate how accurately a predictive model will perform in practice. In a prediction problem, a model is usually given a dataset of known data on which training is run (training dataset), and a dataset of unknown data (or first seen data) against which the model is tested (called the validation dataset or testing set).The goal of cross validation is to define a dataset to “test” the model in the training phase (i.e., the validation set), in order to limit problems like overfitting, give an insight on how the model will generalize to an independent dataset (i.e., an unknown dataset, for instance from a real problem), etc.
One round of cross-validation involves partitioning a sample of data into complementary subsets, performing the analysis on one subset (called the training set), and validating the analysis on the other subset (called the validation set or testing set). To reduce variability, in most methods multiple rounds of cross-validation are performed using different partitions, and the validation results are combined (e.g. averaged) over the rounds to estimate a final predictive model.
Secara ringkas definisi teori di atas menunjukkan bahwa proses cross validasi melibatkan 2 konsep kelompok data dimana terdapat kelompok data validasi (test data) dan kelompok data rill (training data) yang diambil dari populasi yang sama dan jika dilakukan pemodelan pada dua kelompok data tersebut akan menghasilkan model yang relatif sama. Sedangkan apabila dihasilkan model yang tidak sama maka pada model yang dihasilkan (training data) terdapat masalah overfitting.
Gambar 1. Ilutrasi Data Fitting Berdasarkan Kriteria Cross Validation
Jika kita kembalikan kepada konsepsi bandwith maka fungsi cross validasi diterapkan pada data yang sama, berdasarkan konsepsi rumus di atas, kelompok data validasi (test data) diambil dengan cara menghilangkan nilai titik data ke-i untuk dibandingkan dengan kelompok data keseluruhan (training data) dengan cara iterasi sampai diiperoleh nilai CV yang minimum.
Akaike Information Criterion (AIC)
Konsepsi pada AIC tidak jauh beda dengan konsepsi pada CV. Yang pada intinya mengkomparasikan model yang mungkin dibentuk dari suatu set data yang dapat menghasilkan model dengan kekeliruan seminimal mungkin. Sehingga kaitannya dengan konsepsi regresi spasial khususnya pada pemilihan bandwidth, maka akan dipilih nilai AIC yang dapat meminimalkan kekeliruan model atau meminimalkan hilangnya informasi dari data pada model yang terbentuk.
Jika kita merujuk pada pemahaman dasar tentang AIC dan keluar telebih dahulu dari konsep bandwidth maka AIC dapat dimaknai sesuai dengan definisi dari literatur sebagai berikut.
The Akaike information criterion (AIC) is an estimator of the relative quality of statistical models for a given set of data. Given a collection of models for the data, AIC estimates the quality of each model, relative to each of the other models. Thus, AIC provides a means for model selection.
AIC does not provide a test of a model in the sense of testing a null hypothesis. It tells nothing about the absolute quality of a model, only the quality relative to other models. Thus, if all the candidate models fit poorly, AIC will not give any warning of that.
Misal kita memiliki model-model statistik dari suatu set data. Dengan k adalah jumlah parameter dalam model yang akan ditaksir dan L adalah nilai maksimum dari fungsi likelihood model. Maka AIC dapat dirumuskan secara matematis sebagai berikut :
Dengan kriteria berdasarkan definisi yang didapat dari literatur sebagai berikut,
Given a set of candidate models for the data, the preferred model is the one with the minimum AIC value. Thus, AIC rewards goodness of fit (as assessed by the likelihood function), but it also includes a penalty that is an increasing function of the number of estimated parameters. The penalty discourages overfitting, because increasing the number of parameters in the model almost always improves the goodness of the fit.
Bayesian Information Criterion (BIC)
Sama halnya dengan AIC, BIC berdasar pada fungsi likelihood dari suatu set data. Fungsi dari BIC adalah sebuah kriteria dalam pemilihan model terbaik dari suatu set model (banyak model). Dimana yang menjadi kriteria adalah model yang memiliki nilai BIC yang paling rendah adalah model yang paling baik.
Dimana L adalah nilai maksimum dari fungsi likelihood dari model; n adalah ukuran sampel dan k adalah jumlah parameter model yang ditaksir (termasuk konstantan, koefisien beta dan error).
Pada prinsipnya konsepsi penggunaan BIC dengan AIC adalah sama, yang membedakan adalah pada operator penalti bagi parameter yang digunakan dalam kedua model perumusan. Dimana pada AIC operator penalti yang digunakan adalah “2k” sedangkan pada BIC operator yang digunakan adalah “ln(n)k”.
Dan secara prinsipil perbedaan antara AIC dan BIC yang didapat dari literatur adalah sebagai berikut.
A point made by several researchers is that AIC and BIC are appropriate for different tasks. In particular, BIC is argued to be appropriate for selecting the “true model” (i.e. the process that generated the data) from the set of candidate models, whereas AIC is not appropriate. To be specific, if the “true model” is in the set of candidates, then BIC will select the “true model” with probability 1, as n → ∞; in contrast, when selection is done via AIC, the probability can be less than 1. Proponents of AIC argue that this issue is negligible, because the “true model” is virtually never in the candidate set. Indeed, it is a common aphorism in statistics that “all models are wrong”; hence the “true model” (i.e. reality) cannot be in the candidate set.
Guna memandu pemahaman pada para peneliti atau data master, ada baiknya kita sarankan untuk memahami terlebih dahulu secara mendalam konsep CV dibandingkan dengan AIC dan BIC. CV relatif sederhana (sebagai analogi pahami gambar 1) dalam segi memahami dalam konsepsi matematisnya dibandingkan dengan konsepsi matematis pada AIC dan BIC. Namun secara umum ketiga kriteria CV, AIC dan BIC dalam hal penerapannya pada konsepsi bandwitdh pada pemodelan regresi spasial dapat dijadikan dasar pertimbangan yang saling melengkapi, dikarenakan secara aplikasi (pada software GWR 4) ketiga ukuran tersebut muncul dan dapat dikomparasikan sehingga memudahkan peneliti dalam menentukan pemilihan model regresi spasial yang ideal pada data yang dimilikinya. SEMANGAT MEMAHAMI!!!