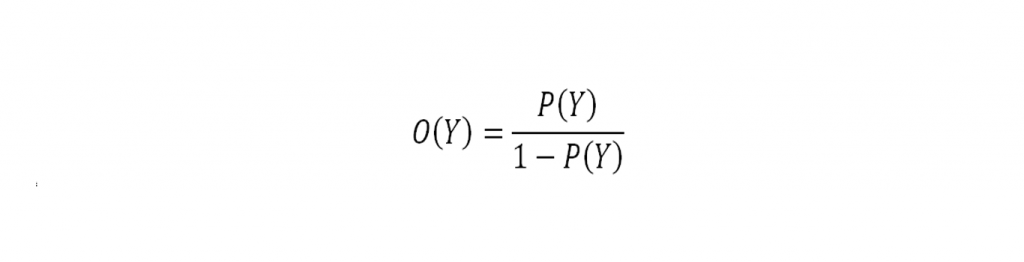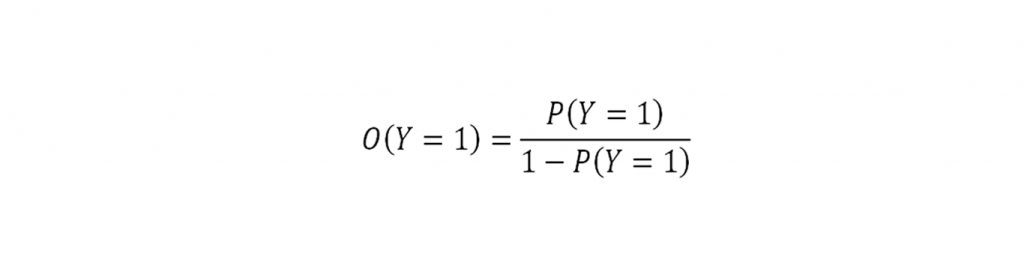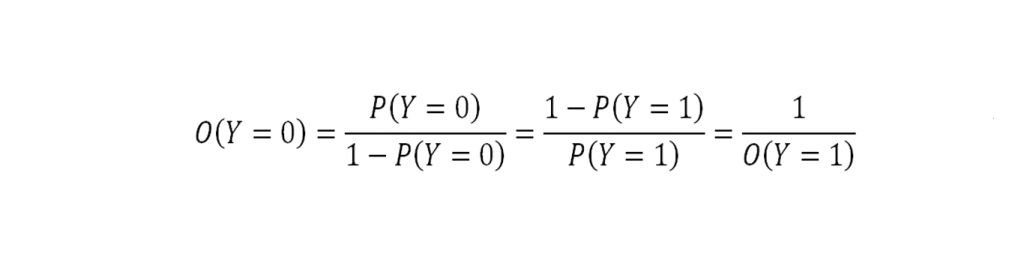Pada kesempatan yang lalu kita sudah menjelaskan secara konsepsi apa itu analisis korelasi kanonik dan perbedaannya dengan bentuk korelasi yang pada umumnya kita kenal pada analisis korelasi bivariate. Untuk kembali mengingatkan kita sedikit pada konsepsi analisis korelasi kanonik, barangkali peneliti atau data master baru saja menemukan artikel ini, analisis korelasi kanonik merupakan jenis analisis yang diperuntukan untuk mencari hubungan antara set variabel bebas (X) dengan set variabel dependen (Y). Jadi dalam hal ini analisis korelasi kanonik termasuk dalam rumpun analisis multivariate.
Pada pembahasan kali ini kita akan coba uraikan tahapan dalam memperoleh nilai korelasi kanonik dengan bantuan software SPSS. Perlu diperhatikan oleh para peneliti atau data master untuk terlebih dahulu mengenal dan memahami konsep analisis korelasi kanonik dan prinsip dalam pembentukannya (Baca artikel : Analisis Korelasi Kanonik dan Analisis Komponen Utama). Hal ini sangat berguna dalam proses pembentukan pemahaman pada tahapan analisis dan pembacaan hasil analisis dengan menggunakan software.
Berikut tahapan dalam penggunaan software SPSS dalam analisis korelasi kanonik.
1. Buka file excel yang terdapat data yang akan kita gunakan dalam analisis korelasi kanonik. Pastikan bahwa data yang kita miliki merupakan data series lebih dari satu variabel X dan lebih dari satu varibel Y. Seperti tampak pada gambar berikut.
2. Setelah kita persiapkan data seperti pada poin 1. Maka langkah selanjutnya adalah buka sofware SPSS dan pada Variabel View definisikan variabel yang kita pakai dalam analisis (variabel X dan Y) serta salin data pada excel ke dalam SPSS pada tampilan Data View. Seperti tampak pada gambar berikut.
Gambar 1. Tampilan Data Pada Data View
3. Langkah selanjutnya adalah melakukan analisis korelasi kanonik. Ada 2 cara melakukan analisis korelasi kanonik. Pertama bagi peneliti atau data master yang sudah melakukan install addins analisis korelasi kanonik, maka dapat langsung mencari pada menu Analyse. Kedua, jika peneliti atau data master tidak menemukan pada menu Analyse maka proses analisis kanonik dapat menggunakan menu Syntax, seperti tampak pada gambar berikut.
Gambar 2. Menu Syntax Pada SPSS
Gambar 3. Tampilan Jendela Syntax
Gambar 4. Jendela Syntax Dengan Intruksi Korelasi Kanonik
4. Setelah memastikan semua syntak yang dituliskan, benar, maka langkah selanjutnya klik menu Run dan klik All. Maka akan muncul tampilan output SPSS untuk analisis korelasi kanonik seperti tampak pada beberapa gambar berikut.
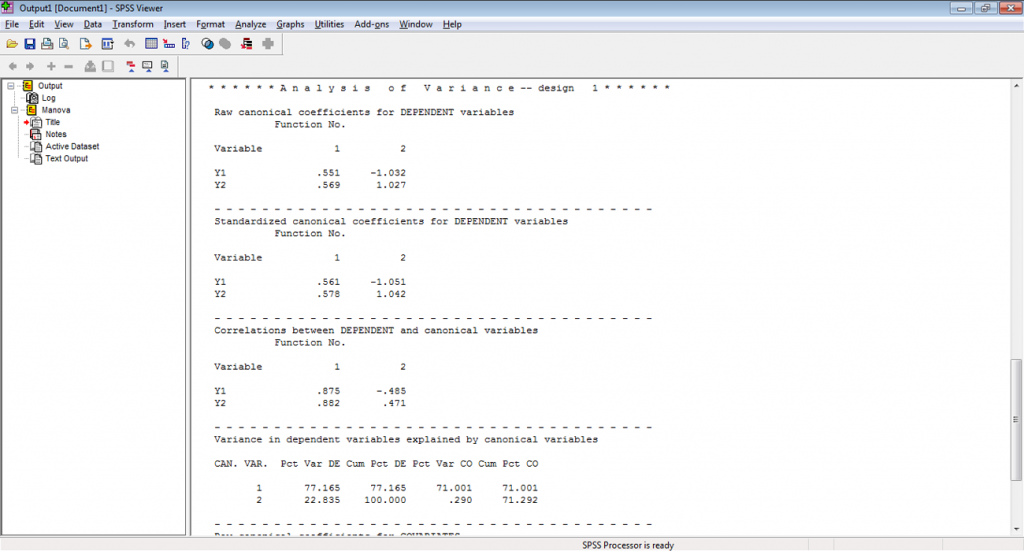
Gambar 5. Output Korelasi Kanonik
Gambar 6. Output Korelasi Kanonik
Gambar 7. Output Korelasi Kanonik
Gambar 8. Output Korelasi Kanonik
5. Setelah mendapatkan output seperti tampak pada poin 4, peneliti atau data master dapat menginterpretasikan hasilnya berdasarkan referensi atau litelatur rujukan serta disesuaikan dengan statemen masalah telah ditentukan di awal.
Yang perlu diperhatikan oleh para peneliti atau data master dalam menginterpretasikan hasil dari analisis korelasi kanonik, setidaknya ada 3 (tiga) aspek utama yaitu pertama, pasangan variabel kanonik mana (canonical variate ke-i) yang menghasilkan nilai korelasi yang signifikan, kedua, menentukan variabel-variabel mana yang memiliki kontribusi yang tinggi dalam menghasilkan canonical variate yang berkorelasi tinggi (koefisien canonical variate) dan ketiga, sejauh mana variasi yang terdapat pada variabel Y dapat dijelaskan oleh variabel X pada canonical covariate yang signifikan serta berkorelasi tinggi tersebut. Untuk menambah atau mengawali pemahaman akan hal tersebut para pembaca dapat membaca artikel kita terkait PCA, analisis faktor dan analisis diskriminan secara berurutan sehingga menguatkan pada proses interpretasi hasil analisis yang akan dilakukan. SEMANGAT MENCOBA!!!
Kita akan sedikit review kembali pembahasan kita terkait SEM dan SEM PLS, yang banyak sekali didapati kebingungan penggunaannya pada sebagian peneliti atau data master yang masuk melalui beberapa pertanyaan kepada kita. Bahwa peneliti tidak perlu memaksakan data yang dimiliki untuk memilih SEM sebagai final tools untuk menghasilkan model struktural atas data yang dimiliki, sedangkan data tersebut memiliki banyak kelemahan dalam pemenuhan asumsi model SEM.
Tidak sedikit akhirnya peneliti atau data master melakukan manipulasi data (terutama pada penelitian sosial-angket) hanya agar diperoleh output model SEM dengan LISREL (salah satunya). Perlu dipahami bahwa ada alternatif lain bagi peneliti atau data master dalam menghasilkan model struktural atas data yang dimiliki ketika asumsi-asumsi model SEM tidak terpenuhi yaitu dengan SEM-PLS, hal ini agar peneliti atau data master tetap dapat menjaga keaslian hasil dari penelitian yang dilakukan.
Lebih dalam terkait dengan SEM dan SEM-PLS kita akan uraikan pada bagian berikut.
Pengertian PLS
Dalam sebuah penelitian sering kali peneliti dihadapkan pada kondisi di mana ukuran sampel cukup besar, tetapi memiliki landasan teori yang lemah dalam hubungan di antara variable yang dihipotesiskan. Namun tidak jarang pula ditemukan hubungan di antara variable yang sangat kompleks, tetapi ukuran sampel data kecil. Partial Least Square (PLS) adalah salah satu metode alternative Structural Equation Modeling (SEM) yang dapat digunakan untuk mengatasi permasalahan tersebut.
Terdapat dua pendekatan dalam Structural Equation Modeling (SEM), yaitu SEM berbasis covariance (Covariance Based-SEM, CB-SEM) dan SEM dengan pendekatan variance (VB-SEM) dengan teknik Partial Least Squares (PLS-SEM). PLS-PM kini telah menjadi alat analisis yang popular dengan banyaknya jurnal internasional atau penelitian ilmiah yang menggunakan metode ini. Partial Least Square disingkat PLS merupakan jenis analisis SEM yang berbasis komponen dengan sifat konstruk formatif. PLS pertama kali digunakan untuk mengolah data di bidang economertrics sebagai alternative teknik SEM dengan dasar teori yang lemah. PLS hanya berfungsi sebagai alat analisis prediktor, bukan uji model.
Semula PLS lebih banyak digunakan untuk studi bidang analytical, physical dan clinical chemistry. Disain PLS dimaksudkan untuk mengatasi keterbatasan analisis regresi dengan teknik OLS (Ordinary Least Square) ketika karakteristik datanya mengalami masalah, seperti : (1). ukuran data kecil, (2). adanya missing value, (3). bentuk sebaran data tidak normal, dan (4). adanya gejala multikolinearitas. OLS regression biasanya menghasilkan data yang tidak stabil apabila jumlah data yang terkumpul (sampel) sedikit, atau adanya missing values maupun multikolinearitas antar prediktor karena kondisi seperti ini dapat meningkatkan standard error dari koefisien yang diukur (Field, 2000 dalam Mustafa dan Wijaya, 2012:11).
PLS yang pada awalnya diberi nama NIPALS (Non-linear Iterative Partial Least Squares) juga dapat disebut sebagai teknik prediction-oriented. Pendekatan PLS secara khusus berguna juga untuk memprediksi variable dependen dengan melibatkan sejumlah besar variable independen. PLS selain digunakan untuk keperluan confirmatory factor analysis (CFA), tetapi dapat juga digunakan untuk exploratory factor analysis (EFA) ketika dasar teori konstruk atau model masih lemah. Pendekatan PLS bersifat asymptotic distribution free (ADF), artinya data yang dianalisis tidak memiliki pola distribusi tertentu, dapat berupa nominal, kategori, ordinal, interval dan rasio.
Pendekatan PLS lebih cocok digunakan untuk analisis yang bersifat prediktif dengan dasar teori yang lemah dan data tidak memenuhi asumsi SEM yang berbasis kovarian. Dengan teknik PLS, diasumsikan bahwa semua ukuran variance berguna untuk dijelaskan. Karena pendekatan mengestimasi variable laten diangap kombinasi linear dari indikator, masalah indereminacy dapat dihindarkan dan memberikan definisi yang pasti dari komponen skor. Teknik PLS menggunakan iterasi algoritma yang terdiri dari serial PLS yang dianggap sebagai model alternative dari Covariance Based SEM (CB-SEM). Pada CB-SEM metode yang dipakai adalah Maximum Likelihood (ML) berorientasi pada teori dan menekankan transisi dari analisis exploratory ke confirmatory. PLS dimaksudkan untuk causal-predictive analysis dalam kondisi kompleksitas tinggi dan didukung teori yang lemah.
Seperti penjelasan di muka, metode PLS juga disebut teknik prediction-oriented. Pendekatan PLS secara khusus berguna untuk meprediksi variable dependen dengan melibatkan banyak variable independen. CB-SEM hanya mampu memprediksi model dengan kompleksitas rendah sampai menengah dengan sedikit indikator.
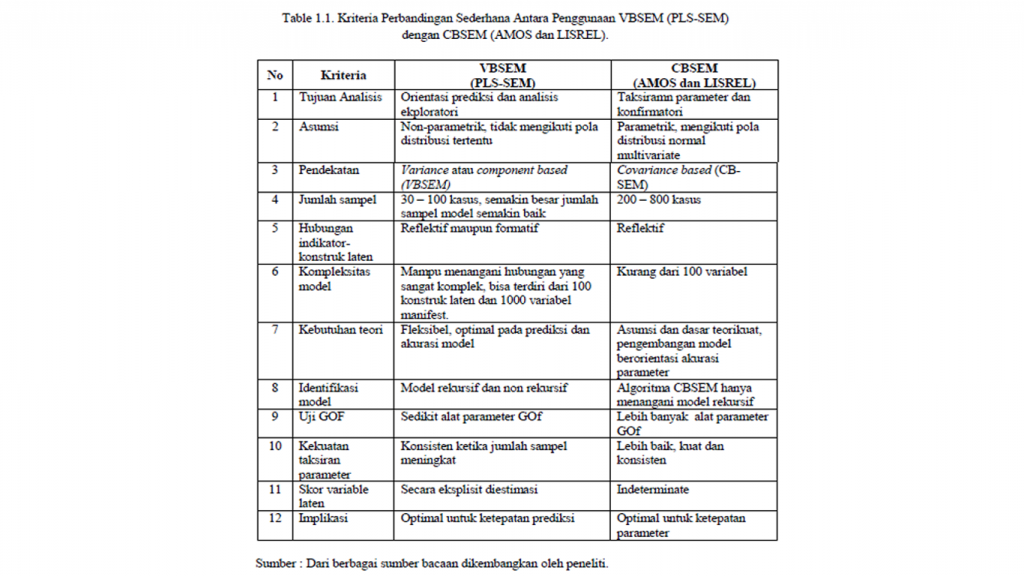
VB-SEM (PLS-SEM ) vs. CB-SEM (AMOS dan LISREL)
Analisis SEM secara umum dapat dibedakan menjadi Variance Based SEM (VB SEM) dan Covariace Based SEM (CBSEM). Pendekatan PLS-SEM didasarkan pada pergeseran analisis dari pengukuran estimasi parameter model menjadi pengukuran prediksi model yang relevan. PLS-SEM menggunakan algoritma iteratif yang terdiri atas beberapa analisis dengan metode kuadrat terkecil biasa (Ordinary Least Squares). Oleh karena itu, dalam PLS-SEM persoalan identifikasi tidak penting. PLS-SEM justru mampu menangani masalah yang biasanya muncul dalam analisis SEM berbasis kovarian. Pertama, solusi model yang tidak dapat diterima (inadmissible solution) seperti munculnya nilai standardized loading factor > 1 atau varian bernilai 0 atau negatif. Kedua, faktor indeterminacy yaitu faktor yang tidak dapat ditentukan seperti nilai amatan untuk variable laten tidak dapat diproses. Karena PLS memiliki karakteristik algoritma interatif yang khas, maka PLS dapat diterapkan dalam model pengukuran reflektif maupun formatif. Sedangkan analisis CB-SEM hanya menganalisis model pengukuran reflektif (Yamin dan Kurniawan, 2011:15).
Dengan demikian, PLS-SEM dapat dikatakan sebagai komplementari atau pelengkap CB SEM (AMOS dan LISREL) bukannya sebagai pesaing. Terdapat 10 kriteria perbandingan sederhana antara penggunaan VBSEM (PLS–SEM) dengan CBSEM (AMOS dan LISREL) dapat dilihat pada Table 1.1.
Dengan berbekal informasi di atas, diharapakan dapat memperjelas bagi peneliti atau data master dalam menerapkan data pada model struktural yang hendak di bentuknya, SEM atau SEM-PLS. Diharapkan juga bahwa peneliti atau data master tidak memaksakan model SEM pada data sedangkan pemenuhan asumsi pada pemodelan SEM sangat lah kurang (banyak kasus dengan memanipulasi data – terutama pada penelitian sosial). Dari informasi di atas jelaslah bahwa dengan penggunaan SEM-PLS sangat tepat untuk peneliti atau data master yang memiliki data yang memiliki banyak kekurangan dalam pemenuhan asumsi model SEM. Hal ini guna memperoleh hasil maksimal dari pemodelan SEM yang dilakukan dan secara prinsip SEM-PLS merupakan alat yang sama dalam pencarian jawaban atas pemodelan struktural suatu teori atas data yang dimiliki. SEMANGAT MEMAHAMI!!!
Banyak pertanyaan yang masuk kepada kita terkait dengan uji kebaikan model dari model SEM PLS dan output yang dihasilkan oleh software SmartPLS. Pada prinsipnya secara umum ada kesamaan ketika mengevaluasi model SEM antara SEM-PLS dengan SEM. Secara kasat mata peneliti atau data master dapat melihat langsung nilai loading faktor dan nilai statistik t yang muncul langsung pada diagram model untuk menentukan apakah terdapat pengaruh variabel manifest terhadap latenya serta variabel endogen terhadap eksogen berarti ataukah tidak (signifikansi).
Karena memang basis pengolahannya yang berbeda (Baca Artikel : SmartPLS) dimana SEM menggunakan matriks kovarians atau korelasi sebagai basis pengolahannya sedangkan SEM PLS menggunakan matriks varians sebagai basis pengolahannya sehingga memungkinkan menghasilkan evaluasi yang berbeda terhadap output hasilnya. Selain itu, pada SEM PLS dapat digunakan jumlah sampel yang kecil dibandingkan pada SEM, sehingga SEM PLS sering disebut juga non parametrik pada analisis struktural dan SEM merupakan parametrik pada analisis struktural sehingga memungkinkan menghasilkan evaluasi yang berbeda terhadap output hasilnya pula.
Yang sedikit mencolok yang membedakan pengujian kebaikan model antara SEM dengan SEM PLS adalah terletak dari jumlah pengujian. Dimana pengujian pada SEM PLS lebih sedikit dibandingkan dengan pengujian pada SEM. (Baca Artikel : Uji Kebaikan Model SEM).
Pada kesempatan kali ini kita akan coba uraikan secara singkat penujian kebaikan model SEM PLS berdasarkan teori dan output yang dihasilkan oleh software SmartPLS, sebagai berikut.
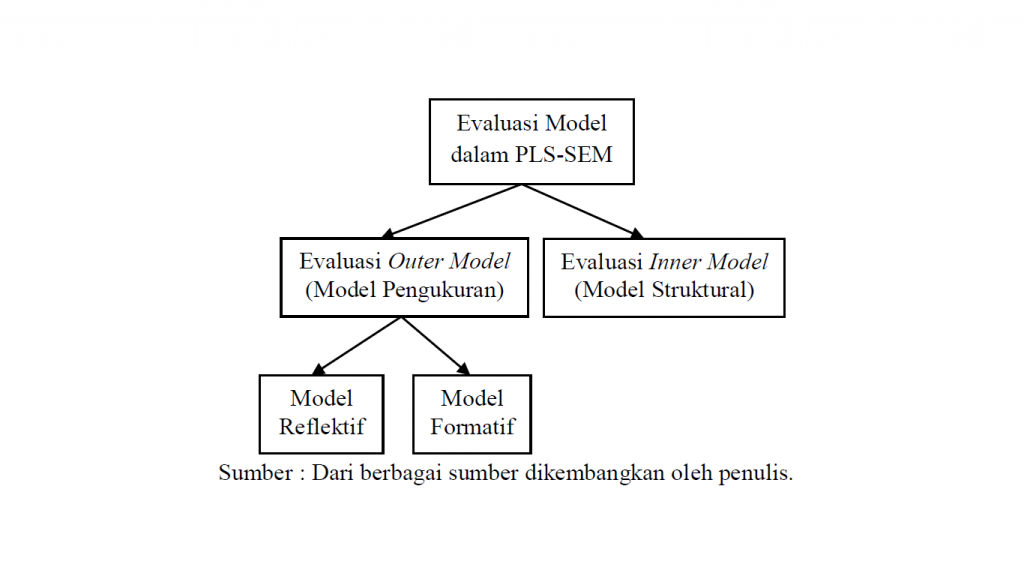
Model hubungan variable laten dalam SEM PLS terdiri dari tiga jenis ukuran, yaitu : (1). Inner model yang menspesifikasikan hubungan antar variable laten berdasarkan substantive theory, (2). Outer model yang menspesifikasi hubungan antar variable laten dengan indikator atau variable manifest-ntya (disebut measurement model). Outer model sering disebut outer relation yang mendefinisikan bagaimana setiap blok indicator berhubungan dengan variable laten yang dibentuknya. (3). Weight relation, yaitu estimasi nilai dari variable latent.
Individual Item Reliability : pemeriksaan individual item reliability, dapat dilihat dari nilai standardized loading factor. Standardized loading factor menggambarkan besarnya korelasi antara setiap item pengukuran (indikator) dengan konstruknya. Nilai loading factor > 0.7 dikatakan ideal, artinya indicator tersebut dikatakan valid mengukur konstruknya. Dalam pengalaman empiris penelitian, nilai loading factor > 0.5 masih dapat diterima. Dengan demikian, nilai loading factor < 0.5 harus dikeluarkan dari model (di-drop). Nilai kuadrat dari nilai loading factor disebut communalities. Nilai ini menunjukkan persentasi konstruk mampu menerangkan variasi yang ada dalam indikator.
Internal Consistency atau Construct Reliability : kita melihat internal consistency reliability dari nilai Cronbach’s Alpha dan Composite Reliability (CR). Composite Reliability (CR) lebih baik dalam mengukur internal consistency dibandingkan Cronbach’s Alpha dalam SEM karena CR tidak mengasumsikan kesamaan bobot dari setiap indikator. Cronbach’s Alpha cenderung menaksir lebih rendah construct reliability dibandingkan Composite Reliability (CR). Interpretasi Composite Reliability (CR) sama dengan Cronbach’s Alpha. Nilai batas > 0.7 dapat diterima, dan nilai > 0.8 sangat memuaskan.
Average Variance Extracted (AVE) : Ukuran lainnya dari covergent validity adalah nilai Average Variance Extracted (AVE). Nilai AVE menggambarkan besarnya varian atau keragaman variable manifest yang dapat dimiliki oleh konstruk laten. Dengan demikian, semakin besar varian atau keragaman variable manifest yang dapat dikandung oleh konstruk laten, maka semakin besar representasi variable manifest terhadap konstruk latennya. Fornell dan Larcker (1981) dalam Ghozali (2014:45) dan Yamin dan Kurniawan (2011:18) merokemndasikan penggunaan AVE untuk suatu criteria dalam menilai convergent validity. Nilai AVE minimal 0.5 menunjukkan ukuran convergent validity yang baik. Artinya, variable laten dapat menjelaskan rata-rata lebih dari setengah varian dari indikator-indikatornya. Nilai AVE diperoleh dari penjumlahan kuadrat loading factor dibagi dengan error. Ukuran AVE juga dapat digunakan untuk mengukur reliabilitas component score variable latent dan hasilnya lebih konservatif dibandingkan dengan composite reliability (CR). Jika semua indicator distandarkan, maka nilai AVE akan sama dengan rata-rata nilai block communalities.
> Discriminant Validity : discriminant validity dari model reflektif dievaluasi melalui cross loading, kemudian dibandingkan nilai AVE dengan kuadrat dari nilai korelasi antar konstruk (atau membandingkan akar kuadrat AVE dengan korelasi antar konstruknya). Ukuran cross loading adalah membandingkan korelasi indikator dengan konstruknya dan konstruk dari blok lainnya. Bila korelasi antara indicator dengan konstruknya lebih tinggi dari korelasi dengan konstruk blok lainnya, hal ini menunjukkan konstruk tersebut memprediksi ukuran pada blok mereka dengan lebih baik dari blok lainnya. Ukuran discriminant validity lainnya adalah bahwa nilai akar AVE harus lebih tinggi daripada korelasi antara konstruk dengan konstruk lainnya atau nilai AVE lebih tinggi dari kuadrat korelasi antara konstruk.
2. Evaluasi Model Pengukuran Formatif
Sedikitnya ada lima isu kritis untuk menentukan kualitas model formatif, yaitu :
Content specification, berhubungan dengan cakupan konstruk laten yang akan diukur. Artinya kalau mau meneliti, peneliti harus seringkali mendiskusikan dan menjamin dengan benar spesifikasi isi dari konstruk tersebut.
Specification indicator, harus jelas mengidentifikasi dan mendefinisikan indikator tersebut. Pendefinisian indicator harus melalui literature yang jelas serta telah mendiskusikan dengan para ahli dan divalidasi dengan beberapa pre-test.
Reliability indicator, berhubngan dengan skala kepentingan indicator yang membentuk konstruk. Dua rekomendasi untuk menilai reliability indicator adalah melihat tanda indikatornya sesuai dengan hipotesis dan weight indicator-nya minimal 0.2 atau signifikan.
Collinearity indicator, menyatakan antara indikator yang dibentuk tidak saling berhubungan (sangat tinggi) atau tidak terdapat masalah multikolinearitas dapat diukur dengan Variance Inflated Factor (VIF). Nilai VIF > 10 terindikasi ada masalah dengan multikolinearitas, dan
External validity, menjamin bahwa semua indikator yang dibentuk dimasukkan ke dalam model.
Evaluasi Inner Model (Model Struktural)
Setelah mengevaluasi model pengukuran konstruk/variabel, tahap selanjutnya adalah menevaluasi model struktural atau inner model.
Langkah pertama adalah mengevaluasi model struktural adalah melihat signifikansi hubungan antar konstruk/variabel. Hal ini dapat dilihat dari koeisien jalur (path coeficient) yang menggambarkan kekuatan kekuatan hubungan antar konstruk. Tanda atau arah dalam jalur (path coefficient) harus sesuai dengan teori yang dihipotesiskan, signifikansinya dapat dilihat pada t test atau CR (critical ratio) yang diperoleh dari proses bootstrapping (resampling method).
Langkah kedua adalah mengevaluasi nilai R2. Interpretasi nilai R2 sama dengan interpretasi R2 regresi linear, yaitu besarnya variability variabel endogen yang mampu dijelaskan oleh variabel eksogen. Menurut Chin (1998) dalam Yamin dan Kurniawan (2011:21) kriteria R2 terdiri dari tiga klasifikasi, yaitu : nilai R2 0.67, 0.33 dan 0.19 sebagai substansial, sedang (moderate) dan lemah (weak). Perubahan nilai R2 dapat digunakan untuk melihat apakah pengaruh variabel laten eksogen terhadap variabel laten endogen memiliki pengaruh yang substantif. Hal ini dapat diukur dengan effect size f2. Menurut Cohen (1988) dalam Yamin dan Kurniawan (2011:21) Effect Size f2 yang disarankan adalah 0.02, 0.15 dan 0.35 dengan variabel laten eksogen memiliki pengaruh kecil, moderat dan besar pada level struktural
Untuk memvalidasi model struktural secara keseluruhan digunakan Goodness of Fit (GoF). GoF indeks merupakan ukuran tunggal untuk memvalidasi performa gabungan antara model pengukuran dan model struktural. Nilai GoF ini diperoleh dari akar kuadrat dari average communalities index dikalikan dengan nilai rata-rata R2 model. Nilai GoF terbentang antara 0 sd 1 dengan interpretasi nilai-nilai : 0.1 (Gof kecil), 0,25 (GoF moderate), dan 0.36 (GoF besar).
Pengujian lain dalam pengukuran struktural adalah Q2predictive relevance yang berfungsi untuk memvalidasi model. Pengukuran ini cocok jika variabel latin endogen memiliki model pengukuran reflektif. Hasil Q2predictive relevance dikatakan baik jika nilainya > yang menunjukkan variabel laten eksogen baik (sesuai) sebagai variabel penjelas yang mampu memprediksi variabel endogennya.
Seperti analisis menggunakan CB-SEM, analisis dengan PLS-SEM juga menggunakan dua tahapan penting, yaitu measurement model dan structural model. Data dalam measurement model dievaluasi untuk menentukan validitas dan reliabilitasnya. Bagian dari measurement model terdiri dari : (1). Individual loading dari setiap item pertanyaan. (2). Internal Composite Reliability (ICR). (3). Average Variance Extracted (AVE), dan (4). Discriminant Validity.
Apabila data memenuhi syarat dalam measurement model, maka tahap selanjutnya adalah mengevaluasi structural model. Dalam structural model hipotesis diuji melalui signifikansi dari : (1). Path coefficient, (2). T-statistic, dan (3). r-squared value. SEMANGAT MEMAHAMI!!!
Mungkin banyak yang bertanya-tanya ketika kita sedang coba mempelajari dan memahami analisis regresi rumpun regresi dengan variabel dependen (Y) berupa kategori. Karena istilah tersebut sering sekali muncul dan merupakan salah satu nilai yang penting dalam interpretasi hasil analisis dari analisis regresi dalam rumpun analisis regresi logistik.
Selain itu, bagi para peneliti terutama dalam penelitian medis pun istilah odds atau odds rasio seringkali muncul karena berkaitan dengan pola perbandingan (efektivitas) dan ditemukan dalam penyelesaian kasus dengan menggunakan pendekatan tabel tabulasi silang (cross tabulasi).
Ada baiknya sebelum kita mempelajari lebih lanjut terkait alat analisis yang ada kaitannya dengan nilai odds dan odds rasio, kita coba untuk memahami pengertian dan pemaknaan dari nilai odds dan odds rasio tersebut. Pada kesempatan kali ini kita akan coba ulas dan pelajari bersama kedua nilai dan istilah tersebut.
Odds
Probabilitas (peluang) adalah pernyataan kuantitatif mengenai kemungkinan suatu kejadian akan terjadi. Ukuran probabilitas dikaitkan dengan suatu kejadian Y dan dinyatakan sebagai P(Y) yang bernilai 0 ≤ P(Y) ≤ 1. Odds suatu kejadian Y, dinyatakan sebagai O(Y), adalah rasio probabilitas antara 2 outcome suatu variabel biner, yaitu rasio antara probabilitas terjadinya suatu kejadian Y dengan probabilitas tidak terjadinya kejadian Y tersebut:
Jika peristiwa terjadinya suatu kejadian Y dinyatakan dengan nilai Y = 1 dan peristiwa tidak terjadinya kejadian Y dengan nilai Y = 0, maka odds kejadian Y adalah:
dan odds tidak terjadinya kejadian Y adalah:
Odds Rasio
Pada studi epidemiologi dengan prediktor biner sebagai variabel independen dan respons yang juga biner sebagai variabel dependen, ringkasan data dapat disajikan dalam bentuk tabel 2×2 berikut:
Tabel 1. Tabulasi Silang 2 x 2
Odds bersyarat Y, yaitu odds Y dengan syarat prediktor X ada ialah:
Sedangkan odds Y dengan syarat prediktor X tidak ada yaitu:
Rasio antara keduanya dinamakan rasio odds (odds ratio), sebagai estimasi untuk nilai rasio odds dalam populasi, yaitu:
Sedangkan, untuk prediktor kontinu, rasio odds dihitung sebagai rasio odds untuk dua keadaan dengan perubahan 1 satuan satuan variabel independen, dengan asumsi rasio ini konstan di sepanjang perubahan nilai variabel independen, yang ringkasan datanya disajikan pada tabel berikut:
Rasio odds untuk prediktor kontinu adalah:
Sebagai gambaran redaksi interpretasi nilai odds rasio yang diperoleh dari hasil perhitungan adalah sebagai berikut : “Odds rasio disini dihitung dengan membandingkan pola makan baik dengan pola makan buruk. Odds rasio untuk hasil diabetes dihitung dengan membandingkan peluang memiliki pola makan baik yang diabetes dengan memiliki pola makan buruk yang diabetes. Odds rasio berdasarkan output SPSS dapat yaitu 0.434. Artinya pola makan baik memiliki resiko untuk diabetes 0.434 kali dibandingkan dengan memiliki pola makan buruk. Hal ini mengindikasikan bahwa dengan pola makan baik akan mengurangi resiko untuk terkena diabetes”
Seperti yang telah kita ketahui bersama bahwa penggunaan odds dan odds rasio sangat berguna dalam membantu menginterpretasikan hasil dari beberapa alat analisis statistik. Beberapa diantaranya adalah penggunaannya pada analisis tabulasi silang dan analisis regresi logistik. Dimana odds dan odds rasio bermanfaat dalam menginterpretasikan besaran nilai peluang suatu kejadian atas kejadian yang lain. Sehingga membantu peneliti atau data master dalam memahami suatu kesimpulan dari analisis data yang telah dilakukan. SEMANGAT MEMAHAMI!!!
Pada kesempatan sebelumnya kita sudah mengupas secara konsepsi analisis regresi ordinal atau analisis regresi dengan data variabel dependen (Y) merupakan kategori berjenjang (level atau tingkatan) lebih dari 2 kategori. Sedikit mereview pembahasan artikel kita tentang analisis regresi ordinal bahwa model yang dihasilkan nantinya akan ada sebanyak k-1 buah persamaan regresi logistik (regesi logistik biner). Sehingga untuk memahami persamaan regresi ordinal yang nantinya dihasilkan, para peneliti atau data master diharapkan memahami pula konsepsi dari analisis regresi logistik (data binner).
Hal lain yang perlu diperhatikan pula oleh para peneliti atau data master adalah adanya variabel kategori lainnya dalam model regresi yang dibentuk. Utamanya adalah variabel kategori (dummy) pada variabel independen (X) sehingga berlaku pula aturan pemodelan dengan melibatkan variabel X dummy (baca artikel : regresi variabel X dummy). Kenapa kita ulas demikian karena dalam penggunaannya, tidak jarang variabel-variabel independen dummy ikut dilibatkan dalam pemodelan dan pada aplikasi SPSS juga difasilitasi bentuk variabel independen kategori (dummy) dalam proses pemodelannya.
Agar lebih tergambar dan lebih jelas lagi dalam pengaplikasiannya, pada bagian berikut kita akan coba uraikan tahapan-tahapan penggunaan SPSS dalam menghasilkan model regresi ordinal.
1. Persiapkan data yang kita miliki dalam file excel seperti tampak pada gambar berikut. Pastikan variabel yang kita miliki merupakan variabel kategori untuk variabel Y-nya (lebih dari 2 kategori berjenjang), sesuai dengan judul yang kita akan ujikan pada kesempatan kali ini.
2. Buka software SPSS lalu definisikan variabel penelitian kita pada jendela Variabel View, setelahnya masukan data ke dalam software SPSS melalui jendela Data View. Dalam tampilan SPSS akan terlihat seperti gambar berikut :
Gambar 1. Data View Gambar 2. Variabel View
3. Pilih menu Analyze lalu klik Regression lalu pilih Ordinal lalu klik, maka akan muncul jendela SPSS seperti gambar di bawah ini, yang berisikan menu-menu kelengkapan analisis regresi dengan model ordinal. Masukan variabel-variabel pada sisi sebelah kanan ke dalam kolom pendefinisian variabel yaitu dependent (untuk variabbel Y dummy berjenjang), factors (untuk variabel X dummy) dan covariate (untuk variabel X dengan skala ukur interval/rasio) guna menghasilkan model regresi ordinal yang kita inginkan
4. Klik menu Option untuk mendefinisikan proses yang akan dilakukan oleh SPSS terhadap data dalam proses pemodelan regresi ordinal. Perlu diperhatikan perubahan pada menu option dilakukan harus disesuaikan dengan pemahaman peneliti terhadap teori yang mendasarinya, jika tidak peneliti dapat menggunakan settingan default pada SPSS. Setelah kita definisikan lalu klik Continue.
5. Klik menu Output, pada menu ini didefinisikan seluruh output yang diharapkan dari proses pemodelan regresi ordinal. Sama halnya dengan pada menu Option, perubahan pada menu output dapat dilakukan disesuaikan dengan pemahaman peneliti terhadap teori dan tujuan penggunaan model regresi ordinal yang mendasarinya, jika tidak peneliti dapat menggunakan settingan default pada SPSS. Lalu klik Continue.
6. Dan pada dua menu lainnya yaitu Location dan Scale digunakan dengan berdasarkan pemahaman peneliti terhadap teori yang mendasarinya, jika tidak peneliti dapat menggunakan settingan default pada SPSS.
7. Maka tampilan akhir jendela pemodelan regresi ordinal akan tampak seperti gambar berikut. Jika sudah yakin dengan semua kelengkapan analisis yang akan di terapkan pada data, lalu klik OK.
8. Maka SPSS akan memproses pembentukan model regresi ordinal dan akan muncul tampilan output SPSS seperti gambar di bawah ini.
Gambar 1. Output SPSS Goodness of Fit Model Gambar 2. Koefisien Regresi Ordinal
9. Selain itu dengan melihat pada SPSS Data Editor, kita dapat melihat nilai peluang dan kategori hasil prediksi yang dihasilkan dari model regresi ordinal yang dihasilkan. Seperti tampak pada gambar di bawah ini.
Dari tahapan pengujian data atas model regresi ordinal yang perlu dicermati oleh peneliti adalah hasil peluang kategori hasil prediksi yang dihasilkan oleh model. Peluang yang dihasilkan seperti telah dijelaskan pada artikel sebelumnya adalah untuk kepentingan pengelompokan salah satunya. Dan lainnya untuk diinterpretasikan secara langsung penggolongan unit data atas suatu kelompok yang diujikan (merujuk pada pengelompokan pada variabel Y). Pengelompokan yang dihasilkan salah satunya berguna dalam menghasilkan nilai rasio kemungkinan atau odds yang dapat sangat membantu peneliti dalam interpretasi perbandingan antar kategori (sama halnya dengan analisis regresi logit binner).
Sampai jumpa pada pembahasan artikel selanjutnya. SELAMAT MENCOBA!!!
Ada beberapa kriteria kebaikan model yang harus terpenuhi oleh model persamaan yang dihasilkan oleh rumpun analisis regresi logistik (biner, multinomial dan atau ordinal). Pada prinsipnya pemahaman dasar dapat diperoleh dari analisis regresi karena secara umum adalah sama yaitu menguji secara umum model persamaan regresi dan uji keberartian variabel secara parsial.
Beberapa teknik pengujian pada rumpun analisis regresi logistik (biner, multinomial dan atau ordinal) diantaranya uji rasio likelihood, uji wald, deviansi, uji hosmer-lemeshow dan kriteria informasi. Secara definisi dan pemahaman dalam penggunaannya kita akan coba uraikan secara singkat satu per satu pada uraian berikut.
Uji Rasio Likelihood
Misalkan dimiliki 2 model regresi logistik untuk dataset yang sama dengan model regresi kedua tersarang dalam model pertama. Maka model pertama dinamakan model lengkap (full model-model dengan semua parameter), sedangkan model kedua dinamakan model tereduksi (reduced model-model hanya konstanta atau sebagian parameter).
Uji statistik untuk memperbandingkan kedua model tersebut dapat dilakukan dengan uji rasio likelihood. Jika model pertama memiliki fungsi likehood −2 ln L1 dengan (p + k) parameter dan model kedua memiliki fungsi likehood −2 ln L2 dengan p parameter, maka statistik pengujinya adalah:
Dimana persamaan di atas berdistribusi khi-kuadrat dengan derajat bebas (p + k) – p = k. Seandainya hasil uji statistik tidak menunjukkan perbedaan antara model lengkap dengan model tereduksi, maka berdasarkan prinsip parsimoni yang dipilih adalah model tereduksi.
Uji Wald
Dengan uji rasio likelihood dapat diuji kemaknaan 1 ataupun beberapa prediktor (variabel bebas) sekaligus. Jika uji melibatkan dua atau lebih prediktor dan diperoleh hasil bermakna, tidak diketahui prediktor mana saja yang menyebabkan kemaknaan tersebut. Uji Wald menguji kemaknaan tiap prediktor satu demi satu, masing-masing terhadap hipotesis H0 : bj = 0.
Sebagian ahli Statistika menganggapnya sebagai pengujian ganda (multiple testings) yang memerlukan koreksi untuk kesalahan tipe I-nya, misalnya dengan metode Bonferroni.
Statistik penguji untuk uji Wald adalah:
Dimana persamaan di atas berdistribusi normal baku. Jika hendak digunakan koreksi Bonferroni, maka seandainya terdapat (p + 1) parameter dalam model (b0 ,b1, . . . ,bp ) dan akan digunakan tingkat signifikansi, maka batas kemaknaan yang seharusnya digunakan adalah:
Deviansi
Deviansi (deviance) merupakan ukuran kebaikan-suai (goodness of fit; GOF) yang lazim digunakan untuk model regresi logistik. Deviansi adalah rasio antara fungsi likelihood model peneliti dengan fungsi likelihood model jenuh:
Lc : Likelihood model peneliti, yaitu model yang menggunakan estimasi koefisien regresi b dan akan dihitung deviansinya. Lmax : Likelihood model jenuh
Model jenuh (saturated model) adalah model yang jumlah parameternya sama dengan ukuran sampel. Model jenuh akan menghasilkan prediksi nilai-nilai respons yang sempurna:
Deviansi memiliki rentang nilai yang berkisar dari nol sampai dengan positif tak berhingga. Jika model peneliti memiliki (p + 1) parameter, maka deviansinya dianggap berdistribusi khi-kuadrat dengan derajat bebas {(n – (p + 1)} = (n – p – 1). Uji hipotesis kebaikan-suai dengan statistik deviansi menguji hipotesis H0 : Model sesuai data vs H1 : Model tak-sesuai data.
Dalam kenyataannya, uji hipotesis kebaikan-suai dengan statistik deviansi ini dapat menggunakan individu anggota sampel ataupun kelompok pola kovariat sebagai unit analisis. Kelompok pola kovariat (covariate pattern group) adalah kelompok yang beranggotakan subjek yang memiliki himpunan nilai prediktor yang sama. Penggunaan unit analisis yang berbeda ini akan menghasilkan nilai statistik penguji yang berbeda (rumus perhitungannya memang berbeda) dengan derajat bebas yang berbeda pula.
Pada uji hipotesis yang menggunakan kelompok pola kovariat sebagai unit analisis, maka jika jumlah kelompok pola kovariat sama dengan k, statistik penguji dianggap berdistribusi khi-kuadrat dengan derajat bebas {k – (p + 1)} = (k – p – 1).
Statistik deviansi juga dapat digunakan pada uji rasio likelihood yang memperbandingkan dua model hirarkis, yaitu model pertama tersarang dalam model kedua. Jika model pertama memiliki statistik deviansi Dev1 (b) dengan jumlah parameter (p1 +1) dan model kedua memiliki statistik deviansi Dev2 (b) dengan jumlah parameter (p2 +1), maka statistik penguji rasio likelihood-nya adalah:
Dimana persamaan di atas yang berdistribusi khi-kuadrat dengan derajat bebas (p1 + p2).
Uji Hosmer-Lemeshow
Sebagian ahli menganggap uji kebaikan-suai 1 model dengan statistik deviansi kurang valid karena pada uji untuk 1 model statistik deviansi kurang mendekati distribusi khi-kuadrat. Perbaikannya adalah dengan uji Hosmer-Lemeshow, yang juga merupakan uji khi-kuadrat tetapi bukan terhadap kelompok-kelompok pola kovariat, melainkan kelompok kuantil. Kuantil yang lazim digunakan adalah desil, dengan membagi sampel menjadi 10 desil.
Kriteria Informasi
Kriteria informasi (informational criteria) adalah statistik untuk model yang estimasi parameternya diperoleh dengan memaksimumkan fungsi likelihood-nya, digunakan untuk memperbandingkan kebaikan-suai 2 model hirarkis (salah satu model tersarang dalam model lainnya) ataupun 2 model non-hirarkis. Dua kriteria informasi yang dibahas di sini yaitu AIC (Akaike’s Informational Criteria) dan BIC (Bayesian Informational Criteria).
Pada perbandingan 2 model dengan statistik AIC dan BIC tidak dikenal distribusi statistik penguji, sehingga nilai p-nya tak dapat dihitung. Model yang dipilih adalah model dengan nilai AIC dan BIC yang lebih kecil. Kriteria penilaian selisih relatif nilai AIC antara 2 model A dan B dengan asumsi AICA < AICB menurut Hilbe (2009) adalah:
Tabel 1. Kriteria Penggunaan Nilai AIC
Kriteria penilaian selisih absolut nilai BIC antara 2 model A dan B dengan asumsi BICA < BICB menurut Raftery (1986) adalah:
Tabel 2. Kriteria Penggunaan Nilai BIC
Untuk memperluas dan memperdalam pemahaman terhadap uji kebaikan dari rumpun model regresi logistik, lebih lanjut para peneliti atau data master bisa mempelajari melalui literatur yang lebih lengkap dan mengaplikasikan data riil pada software statistik rujukan (mis : SPSS) untuk mendapatkan gambaran riil angka pengujian yang diperoleh terhadap rumpun model regresi logistik yang dihasilkan dari data. SEMANGAT MEMPELAJARI!!!
Pembahasan terkait dengan ragam analisis regresi kita akan lanjutkan, dimana sebelumnya kita sudah membahas beberapa analisis regresi yang umum orang ketahui dan dalam penggunaannya cukup sering digunakan, beberapa diantaranya adalah analisis regresi logit (data biner), regresi spasial, regresi komponen utama dan yang terakhir kita bahas yaitu regresi multivariate. Yang coba kita akan uraikan secara singkat pada kesempatan kali ini yaitu mengenai analisis regresi ordinal.
Pada pembahasan yang terdahulu kita mengenal istilah ordinal yang merupakan salah satu jenis dari skala ukur data (Baca artikel : Skala Ukur Data). Dalam bahasan skala ukur data, skala ukur ordinal identik dengan pengukuran yang menghasilkan data berupa peringkat atau level. Semisal : tingkat kesukaan, tingkat kesetujuaan, dan sejenisnya. Selain terkait dengan skala ukur ordinal, pada bahasan analisis regresi logit, kita pun sudah cukup banyak mengupas konsepsi penggunaan variabel dependent (Y) dengan nilai biner (0 dan 1) sehingga muncullah istilah odds dan odds ratio dalam konsep interpretasinya.
Nah jika para peneliti sudah mengenal dan memahami apa yang dimaksud dengan skala ukur ordinal dan analisis regresi logit, maka dalam pemahaman terhadap konsep analisis regresi ordinal akan cukup mudah. Karena dalam penerapannya analisis regresi ordinal memadukan antara skala ukur data ordinal pada variabel dependen (Y) pada konsepsi regresi, sehingga dalam proses perhitungannya identik dengan proses perhitungan analisis regresi logit. Yang membedakan hanyalah dari segi kombinasi persamaan regresi yang dihasilkan dari suatu konsepsi variabel dependen (Y) yang berupa tingkatan (lebih dari 2 tingkatan).
Lebih lanjut terkait dengan konsepsi analisis regresi ordinal akan kita uraikan pada bagian selanjutnya.
Konsep Regresi Ordinal
Regresi logistik ordinal adalah pemodelan regresi logistik untuk data variabel tak bebas (Y) dengan respons kategorik ordinal non-biner (kategorik ordinal dengan jumlah kategori lebih daripada dua). Pengolahan data pada regresi logistik ordinal tetap dilakukan dengan menggunakan himpunan nilai variabel bebas (X) yang sama, memisahkannya ke dalam dua bagian dengan respons modifikasi YM = 1 dan YM = 0 seperti pada regresi logistik biasa, tetapi dilakukan secara berulang dengan memindah-mindahkan titik cutoff untuk variabel respons-nya.
Misalkan dimiliki data dengan variabel tak bebas (Y) kategorik ordinal yang memiliki 4 kategori, yaitu kategori I, II, III, dan IV. Maka regresi logistik biasa dilakukan 3 kali terhadap himpunan nilai variabel bebas (X) yang sama, tetapi respons kategori I vs II-III-IV, respons kategori I-II vs III-IV, dan respons kategori I-II-III vs IV. Ketiga titik cutoff variabel respons akan menjadi estimator konstanta dalam tiap model.
Gambar 1. Cut off Persamaan Regresi Ordinal 4 kategori
Sebagai hasil akan diperoleh 3 model regresi dengan estimasi koefisien regresi yang sama (karena menggunakan himpunan nilai variabel bebas (X) yang sama), namun dengan konstanta berbeda (karena menggunakan titik cutoff respons yang berbeda). Ketiga model ini biasanya disebut sebagai 1 model regresi saja, yaitu:
Akan terlihat perbedaanya jika sudah kita proses pemodelannya dengan menggunakan data riil dan aplikasi (salah satunya dengan SPSS). Sehingga bentuk model dan jumlah model yang terbentuk dari hasil variabel dependen yang merupakan data dengan skala ukur ordinal terlihat jelas.
Secara prinsip pengerjaan regresi ordinal serupa dengan regresi logit data biner. Perbedaannya adalah dalam hal banyaknya model regresi yang terbentuk dan kaitannya dengan fungsi pengelompokan. Lebih lanjut para peneliti atau data master bisa mempelajari melalui literatur yang lebih lengkap. Pada kesempatan yang lain kita akan coba perlihatkan pembentukan model regresi ordinal dengan menggunakan software SPSS, agar apa yang telah diuraikan dalam konsepsi regresi ordinal pada artikel ini dapat terlihat jelas pada output SPSS hasil pengolahan data riil. SEMANGAT MEMPELAJARI!!!
Pada kesempatan kali ini kita akan coba uraikan secara singkat pembahasan lanjutan terkait dengan rumpun analisis regresi, yaitu analisis regresi multivariate. Umum yang diketahui oleh peneliti diantaranya analisis regresi sederhana dan analisis regresi multipel (berganda), meskipun pada artikel yang lalu kita sudah menguraikan secara konsepsi pengembangan analisis regresi dalam rangka menanggulangi masalah multikolinearitas, yaitu analisis regresi komponen utama.
Dari segi konsepsi sudah jelas bahwa regresi multivariate berbeda dengan jenis regresi yang kita sudah sebutkan sebelumnya. Akan tetapi dari fungsi pemodelan dan pengujian pengaruh antar variabel masih lah sama. Jika yang diuji pada regresi sederhana atau regresi multipel (berganda) hanya diuji variabel tak bebas (Y) yang tunggal terhadap satu atau lebih variabel bebas (X), sedangkan pada pengujian regresi multivariate yang diuji lebih dari satu variabel tak bebas (Y) terhadap satu atau lebih variabel bebas (X) yang sama. Kelebihan dari regresi multivariate yang mengujikan series dari variabel tak bebas (Y) sekaligus adalah pada pengujiannya dipertimbangkan pula hubungan antar variabel tak bebas (Y) satu dengan yang lainnya dalam pembentukan modelnya.
Lebih lanjut terkait dengan pemaparan konsepsi analisis regresi multivariate akan dijelaskan secara terstruktur pada uraian berikut.
Konsep Analisis Regresi Multivariate
Pada dasarnya analisis regresi multivariate merupakan suatu model regresi yang menyatakan hubungan kausal di antara p buah variabel tak bebas, Y1 , Y2, . . , Yp dan sekumpulan variabel bebas yang serupa X1, X2, . . , Xk. Sehingga setiap variabel tak bebas, Y, diasumsikan mengikuti model regresi linear berikut :
Gambar 1. Model Persamaan Regresi Multivariate
Dengan menggunakan notasi matriks, maka sistem persamaan regresi di atas dapat dinyatakan secara singkat, sebagai berikut :
Gambar 2. Model Matriks Persamaan Regresi Multivariate
Di mana :
Y = Matriks nilai-nilai variabel tak bebas
X = Matriks nilai-nilai variabel bebas
B = Matriks parameter model regresi multivariate
E = Matriks nilai-nilai galat (error)
Note : Sangat disarankan para peneliti menguasai pengolahan data matriks, karena dengan menguasainya, proses perhitungan dengan menggunakan matriks akan sangat memudahkan dalam proses pemahaman dan penerapan data pada pemodelan regresi multivariate.
Penaksiran Koefisien Regresi Multivariate
Dengan formula yang sama yang dapat digunakan untuk mendapatkan nilai taksiran nilai beta pada model regresi multipel, dengan menggunakan matriks, formulasi yang dapat digunakan untuk menaksir nilai beta pada regresi multivariate adalah sebagai berikut,
Gambar 3. Matriks Penaksiran Persamaan Regresi Multivariate
Di mana :
b = matriks nilai dugaan bagi parameter b, berukuran (k+1) x p
(X’X)-1 = invers dari matriks X’X berukuran (k+1) x (k+1), matriks X’X mengandung elemen-elemen jumlah kuadrat dan jumlah hasil kali dari variabel bebas X
(X’Y) = matriks yang mengandung elemen-elemen jumlah hasil kali antara nilai-nilai variabel bebas X dan variabel tak bebas Y, berukuran (k+1) x p.
Uji Signifikansi Model Regresi Multivariate
Berdasarkan uraian yang dikemukakan di atas, tampak bahwa pendugaan model regresi multivariate pada dasarnya serupa dengan pendugaan m buah model univariate, meskipun demikian pengujian hipotesis tentang parameter model adalah berbeda karena analisis regresi univariate tidak memperhatikan ketergantungan yang ada di antara m buah variabel respons atau variabel tak bebas (Y), sedangkan analisis regresi multivariate mempertimbangkan hal tersebut. Dalam analisis univariate diasumsikan bahwa variabel-variabel respons atau variabel tak bebas Y1 , Y2, . . , Yp adalah saling bebas, sedangkan dalam analisis regresi multivariate mempertimbangkan adanya hubungan ketergantungan di antara Y1 , Y2, . . , Yp.
Pengujian terhadap hipotesis terhadap b dilakukan dengan jalan membangun tabel analisis ragam mutivariate (Multivariate Analysis of Variance = MANOVA) berdasarkan perhitungan pada tabel berikut,
Gambar 4. Tabel Manova Pengujian Model Regresi Multivariate
Dengan diperoleh nilai-nilai pada tabel MANOVA di atas, kita dapat menghitung nilai akar-akar ciri (lambda) dari determinan persamaan ciri sebagai berikut, yang mana nilai yang diperoleh dipergunakan dalam pengujian hipotesis terhadap nilai taksiran b.
Gambar 5. Determinan Persamaan Nilai Lambda
Penyelesaian persamaan determinan tersebut di atas diperoleh akar-akar ciri λ1, λ2, . . , λs. Dimana s = min (Vh , p) = min (k + 1, p), Vh = k + 1 merupakan derajat bebas regresi total, sedangkan p adalah banyaknya variabel tak bebas dalam model regresi multivariate. Dengan diperolehnya nilai akar-akar ciri tersebut maka pengujian hipotesis terhadap nilai taksiran b dapat di uji dengan dengan Uji Wilks dan atau statistik V-Bartlet dimana pendekatannya digunakan distribusi Chi-Square (χ2). Berikut rumus yang dapat digunakan oleh peneliti untuk mendapatkan nilai Ʌ (uji Wilks) dan statistik V (uji Bartlet).
Gambar 6. Uji Wilks
Persamaan di atas merupakan uji Wilks (Ʌ) dimana diujikan dengan nilai pada tabel U (lampiran buku-buku multivariate) pada taraf α yang bersesuaian dengan banyaknya variabel tak bebas p, derajat regresi total Vh dan derajat galat Ve.
Gambar 7. Uji Bartlet
Persamaan di atas merupakan uji Bartlet dimana statistik V akan berdistribusi mendekati chi-square dengan derajat bebas v = pk.
Seperti yang tampak pada uraian di atas dalam menghasilkan model regresi multivariate lebih kompleks dibandingkan dengan pembentukan model regresi univariate. Yang perlu diperhatikan awal oleh para peneliti adalah pada penyikapan awal atas konsep penelitian dan variabel penelitian yang kita miliki, agar tidak salah dalam menentukan analisis yang diperlukan apakah hanya cukup dengan menggunakan model regresi univariate ataukah perlu dikembangkan dengan penggunaan model regresi multivariate. Untuk memperdalam pemahaman terhadap konsepsi analisis regresi multivariate sangat disarankan bagi para peneliti untuk membaca literatur-literatur yang membahas permasalah analisis regresi multivariate, utamanya terkait penerapan data pada rumus baik itu secara manual maupun dengan aplikasi software.
Pada kesempatan selanjutnya kita akan coba uraiankan penggunaan data dan software yang tepat dalam meng-olahdata dan variabel penelitian dengan konsep analisis regresi multivariate. SEMANGAT MEMAHAMI.
Kita lanjutkan pembahasan statistik kita, kembali pada pembahasan analisis regresi. Berbeda dengan pembahasan sebelumnya, pada kesempatan kali ini pembahasan analisis regresi yang melibatkan analisis lain yaitu analisis komponen utama, sehingga analisis yang dilakukan dinamakan analisis regresi komponen utama dikarenakan merupakan penggabungan 2 (dua) alat analisis sekaligus yaitu analisis regresi dan analisis komponen utama.
Seperti telah kita paparkan pada 3 (tiga) artikel sebelumnya yaitu analisis regesi, asumsi klasik regresi dan analisis komponen utama, dimana masing-masing analisis memiliki fungsi yang berbeda. (silahkan pelajari artikel kita sebelumnya). Kita fokuskan perhatian kita pada asumsi klasik pada regresi pada bahasan multikolinearitas, dimana pada salah satu bahasan penanggulangannya adalah dengan merangkum variabel bebas (X) yang banyak menjadi hanya beberapa komponen utama saja yaitu dengan metode analisis komponen utama. Dari komponen utama yang terbentuk dapat dilakukan analisis regresi yang menghasilkan model regresi komponen utama yang bebas masalah multikolineritas.
Pembahasan kali ini juga ditujukan bagi para pembaca artikel kami yang menanyakan teknis terkait dengan pembentukan model regresi komponen utama. Berikut disajikan uraian terkait dengan analisis regresi komponen utama.
Konsep Dasar
gambar 1. Persamaan Matematis Komponen Utama
Noted : Notasi Z merupakan variabel angka baku yang disebabkan karena satuan dari variabel X berbeda-beda (baca artikel : Analisis Komponen Utama)
Seperti kita ketahui pada analisis komponen utama pada persamaan di atas, dapat dihitung skor komponen utama dan apabila skor tersebut (K) diregresikan dengan variabel tak bebas (Y) maka model analisis semacam ini dikenal sebagai model regresi komponen utama. Dengan demikian tampak bahwa analisis regresi komponen utama tidak lain merupakan analisis regresi dari variabel tak bebas (Y) terhadap komponen utama yang saling tidak berkorelasi, dimana tiap komponen utama merupakan kombinasi linear dari semua variabel bebas yang telah dispesifikasikan sejak awal.
Oleh karena yang menjadi variabel-variabel bebas dalam analisis regresi komponen utama adalah komponen-komponen yang tidak saling berkorelasi, maka jelas tidak ada lagi masalah multikolinearitas di antara variabel bebas dan oleh karena itu penduga parameter model regresi berdasarkan metode kuadrat terkecil (least square) menjadi shahih (valid).
Dengan demikian teknik analisis komponen utama merupakan suatu teknik analisis untuk mengatasi masalah multikolinearitas dalam analisis regresi klasik yang melibatkan banyak varibel bebas, keunggulan lain dengan tertanganinya masalah multikolinearitas pada model regresi adalah mampu meningkatkan ketepatan pendugaan parameter model regresi dengan jalan meningkatkan derajat bebas galat, karena banyaknya komponen utama yang dilibatkan dalam analisis regresi biasanya dalam jumlah yang lebih sedikit dibandingkan variabel bebas aslinya (variabel X).
Selain itu, keunggulan lain dari penggunaan komponen utama adalah sifat-sifat dari teknik komponen utama yang memungkinkan peneliti untuk melibatkan lebih banyak variabel bebas (X) dalam model regresi, meskipun banyaknya data pengamatan (n) terbatas (jumlah n lebih kecil dibandingkan jumlah variabel X) dan oleh karenanya sering dipergunakan dalam analisis multivariate yang melibatkan banyak variabel dalam model.
Misal apabila kita memberikan notasi K1, K2, . . , Km, sebagai banyaknya komponen utama yang dilibatkan dalam analisis regresi (persamaan di atas) serta Y sebagai variabel tak bebas, maka model regresi komponen utama dapat dirumuskan sebagai berikut :
gambar 2. Persamaan Regresi Komponen Utama
dimana :
Y = variabel tak bebas
Kj = variabel bebas komponen utama yang merupakan kombinasi linear dari semua variabel baku Z (j = 1, 2, . . , m)
W0 = kontanta
Wj = parameter model regresi (koefisien regresi), (j = 1, 2, . . , m)
V = galat
Tahapan Regresi Komponen Utama
Setelah kita memahami konsep yang sudah kita utarakan di atas, setidaknya kita dapat rangkumkan beberapa tahapan yang dapat dilakukan terhadap data atau variabel penelitian yang kita miliki dalam rangkan menganalisisnya dengan menggunakan regresi komponen utma. Berikut tahapannya,
Lakukan pengujian analisis regresi terhadap variabel yang kita miliki untuk memastikan bahwa dalam model regresi terdapat masalah multikolinearitas. Dan atau jika asumsi bahwa variabel bebas terlalu banyak dapat dilakukan langsung dengan langkah analisi komponen utama.
Lakukan analisis komponen utama terhadap variabel bebas (X) untuk mendapatkan komponen utama yang akan dijadikan variabel baru dalam membentuk model regresi komponen utama.
Setelah kita mendapatkan komponen utama yang representatif, langkah selanjutnya adalah menghitung skor komponen utama yang akan digunakan dalam perhitungan analisis regresi komponen utama.
Lakukan analisis regresi yaitu antara data variabel tak bebas (Y) dengan skor komponen utama (variabel bebas K). Sampai dengan tahapan ini kita dapat mengevaluasi signifikansi dari variabel baru yang terbentuk (komponen utama) terhadap variabel tak bebas (Y) dan besaran pengaruh variabel baru (komponen utama) terhadap variabel tak bebas (Y) (R square) yang dihasilkan.
Secara riil bahwa analisis yang kita harapakan adalah untuk mengetahui berpengaruh atau tidaknya dari masing-masing variabel bebas (X) yang kita miliki terhadap variabel tak bebas (Y) atau pun dapat diketahui besaran ataupun kecenderungan mana dari variabel bebas (X) yang paling berpengaruh. Akan tetapi dari hasil poin 4 kita hanya mengetahui bahwa variabel baru (komponen utama K) itu berpengaruh atau tidak terhadap variabel tak bebas (Y). Oleh karenanya diperlukan beberapa tahapan lanjutan yang dilakukan secara manual diantaranya,
Langkah pertama untuk mendapatkan evaluasi berdasarkan variabel bebas (X) maka subtisusikan persamaan komponen utama ke dalam fungsi regresi komponen utama terbentuk. Maka hasil dari proses subtitusi tersebut adalah persamaan regresi komponen utama dengan komponen variabel tidak lagi merupakan fungsi komponen utama K melainkan sudah dalam fungsi variabel Z. (fungsi Z dapat dikonfersikan menjadi variabel X melalui rumus angka baku)
Langkah selanjutnya adalah menguji signifikansi secara manual masing-masing variabel Z terhadap fungsi regresi atas Y. Pengujian menggunakan pendekatan yang sama yaitu dengan menggunakan pendekatan distribusi peluang student t.
Setelah kita memperoleh nilai signifikansi untuk masing-masing variabel Z. Langkah selanjutkan mengkonversikan variabel Z menjadi variabel X berdasarkan pendekatan rumus angka baku. Dari hasil ini kita telah memperoleh model regresi komponen utama yang telah kembali pada fungsi variabel asalnya yaitu variabel X. Hal ini dapat memudahkan dalam proses indentifikasi dan interpretasi hasil pemodelan (regresi komponen utama).
Langkah terakhir adalah menghitung nilai elastisitas X terhadap Y. Nilai ini berfungsi dalam mengukur sensitifitas nilai Y atas perubahan nilai variabel bebas (X). Nilai elastisitas dapat digunakan oleh peneliti untuk menentukan variabel bebas (X) mana yang memberikan perubahan paling besar terhadap variabel tak bebas (Y) (disamping melihat dari besaran nilai koefisien regresi).
Demikian kiranya pemaparan singkat terkait dengan konsepsi dan penggunaan analisis regresi komponen utama. Seperti kita ingatkan di awal bagi para peneliti yang baru saja mengakses artikel ini sangat disarankan untuk membaca 3 (tiga) artikel kita yang berkaitan dengan analisi regesi komponen utama yaitu analisis regesi, asumsi klasik regresi : multikolineariatas dan analisis komponen utama.
Perlu diperhatikan juga bahwa penggunaan analisis regresi komponen utama merupakan alternatif pada 2 (dua) aspek yang harus diperhatikan betul oleh peneliti, pertama, merupakan solusi adanya multikolinearitas antar variabel bebas (X) dan kedua, variabel bebas (X) yang digunakan dalam pemodelan terlalu banyak jika dibandingkan dengan dengan jumlah pengamatan itu sendiri (n).
Oleh karena 2 (dua) sebab itu lah penggunaan analisis regresi komponen utama menjadi beralasan, dikarenakan secara prinsip bahwa penyelesaian masalah penelitian adalah dengan alat yang tepat dan sederhana, bukan lah sebaliknya alat yang kompleks akan tetapi tidaklah efektif, karena akan menjadi suatu kemubadziran dalam prosesnya. SEMANGAT MEMPELAJARI!!!
Untuk kesekian kalinya kita berada pada bahasan analisis pada rumpun analisis multivariat. Kali ini kita masuk pada bahasan yang sangat menarik khususnya bagi rekan peneliti, data master maupun para praktisi bidang usaha, baik itu pada pengembangan produk maupun pengembangan jasa. Mungkin sebagian rekan peneliti, data master maupun para praktisi bidang usaha mengenal atau telah ekspert dengan istilah konjoin atau analisis konjoin. Ya, analisis konjoin sangat membantu sekali bagi rekan-rekan yang bingung atau kesulitan dalam menemukan suatu alat atau metode yang tepat dalam membantu menganalisa data kaitannya dengan fitur produk atau jasa ataupun kesukaan atau preferensi kosumen terhadap produk atau jasa yang kita miliki.
Bisa dibilang analisis konjoin sangat spesial dibandingkan analisis dalam rumpun multivariat lainnya. Namun secara basic pemahaman akan analisis konjoin dapat dibantu dengan pemahaman peneliti atau data master pada konsepsi analisis regresi dan pengujian anova pada rancangan percobaan faktorial. Sebagai gambaran awal bahwa output yang dihasilkan oleh analisis konjoin berupa nilai preferensi konsumen yang dihasilkan dari kombinasi linier pada fitur-fitur produk yang diujikan kepada konsumen, itu dari sisi konsepsi regresi. Pada sisi rancangan percobaan faktorial bahwa analisis konjoin didasarkan atas pertimbangan matang terhadap atribut-atribut atau fitur-fitur produk yang akan diujikan kepada konsumen, sehingga ada baiknya bahwa atribut-atribut atau fitur-fitur yang hendak diujikan kepada konsumen benar-benar representasi kebutuhan atau preferensi konsumen ketika membeli produk.
Analisis konjoin merupakan suatu analisis yang menarik, menarik karena output yang dihasilkan erat kaitannya dengan sukses tidaknya suatu produk ketika di-launching ke market atau dengan kata lain apakah produk tersebut laku atau tidak. Ya, karena pra launching dengan analisis konjoin produk tersebut telah diujicobakan terlebih dahulu sebagai input informasi awalan kepada bagian marketing maupun produksi suatu perusahaan. Jika pun tidak sukses, yang bisa dikoreksi dari penggunaan alat analisis ini adalah penentuan atribut atau fitur yang diuji cobakan di awal apakah sudah tepat atau kah tidak tepat.
Pada beberapa artikel ke depan kita akan coba sedikit kupas konsepsi tentang analisis konjoin, karena merupakan analisis yang kompleks maka akan coba kita uraikan secara bertahap. Berdasarkan buku yang menjadi referensi kita (baca : Multivariate Data Analysis, Pearson New International Edition, Hair dkk) setidaknya terdapat 7 tahapan dalam memahami dan mengaplikasikan konsep analisis konjoin pada penelitian yang akan dilakukan. Cukup panjang dan kompleks memang, perlu kehati-hatian dan ketelitian dalam memahami tiap tahapannya.
Tahap 1. Merumusakan Tujuan dari Analisi Konjoin (Objectives of Conjoint Analysis)
Seperti pada umumnya penelitian, tahapan pertama yang paling menentukan dan membuat suatu penelitian memiliki motivasi dan kekuatan adalah penentuan tujuan. Seperti kita kemukakan di muka, bahwa ada keunikan tersendiri pada analisis konjoin yaitu penerapannya pada aspek “marketing” produk atau jasa, 2 (dua) tujuan utama yang setidaknya harus dipegang oleh peneliti diantaranya :
“To determine the contribution of predictor variables and their levels in the determination of consumer preference”. Dengan pemahaman bahwa analisis konjoin ini ditujukan untuk menentukan nilai kontribusi variabel yang menjelaskan (X) dengan tingkatan atau level yang ada pada variabel tersebut (spesifik fitur) yang dapat menggambarkan keputusan preferensi (pilihan) atau kesukaan konsumen. Dengan analisis konjoin kita dapat mendapatkan paket fitur seperti apa dari produk yang paling disukai oleh konsumen (harga,kemasan, rasa, bentuk, dll).
“To establish a valid model of consumer judgments”. Dengan pemahaman bahwa analisis konjoin ini ditujukan untuk membentuk suatu model yang terbukti sebagai model keputusan konsumen untuk memilih atau membeli produk atau jasa. Bentuk model disini sama halnya pemahaman kita terhadap model regresi, dalam analisis konjoin variabel-variabel dalam model merupakan spesifik fitur (level dalam variabel) yang memiliki kontribusi besar terhadap preferensi konsumen terhadap produk atau jasa.
Setelah kita menetapkan pada dua tujuan tersebut di atas, selanjutnya masih dalam rangka menelaah tujuan analisis konjoin, dari dua tujuan tersebut kita dapati dua pertanyaan penting yang perlu dipertimbangkan secara benar oleh peneliti, diantarannya,
Is it possible to describe all the attributes that give utility or values to the product? Pertanyaan tersebut merepresentasikan apakah para peneliti, data master maupun para praktisi bidang usaha, mungkin untuk menggambarkan semua variabel yang mampu menggambarkan kegunaan atau nilai yang melekat pada produk atau jasa tersebut. Hal ini menjadikan pertimbangan tersendiri bahwa peneliti, data master maupun para praktisi bidang usaha, harus dapat setepat mungkin mendefinisikan produk atau jasanya yang akan ditawarkan kepada konsumen.
What are the key attribute involved in the choice process for this type of product or service?Setelah peneliti, data master maupun para praktisi bidang usaha, yakin atas variabel-variabel yang melekat dan yang mampu menggambarkan produk atau jasa tersebut, maka hal selanjutnya yang perlu dipahami dan diputuskan secara tepat adalah variabel mana saja yang merupakan kunci dalam mempengaruhi konsumen dalam menentukan pilihannya atas produk atau jasa yang ditawarkan nantinya. Karena berdasarkan atas penentuan variabel yang tepat, yang nantinya akan menentukan produk atau jasa tersebut laku atau tidak di pasaran, biasanya penentuan variabel tersebut, salah satunya dapat dilakukan dengan focus group discussion (FGD).
Penetapan tujuan dan jawaban pertanyaan yang tepat pada tahap awal ini sangat menentukan tahapan selanjutnya dalam analisis konjoin. Pada tahapan ini peneliti akan mendapatkan panduan dalam mendapatkan keputusan kunci pada tiap tahapannya.
Tahap 2. Mendesain Analisis Konjoin (The Design of Conjoint Analysis)
Pada tahap ini kita mencoba untuk mempersiapkan kelengkapan analisis konjoin darisisi perencanaan dan teknis. Seperti kita ketahui bahwa pada tahap pertama bisa dikatakan adalah tahapan konsepsi terhadap masalah yang akan coba dicarikan pernyataan keputusan atau solusinya. Nah, pada tahapan ini lah kita mendeskripsikan hal-hal apa saja yang harus dilakukan untuk mendapatkan keputusan atau solusi tersebut pada analisis konjoin. Adapun hal-hal yang perlu diketahui oleh peneliti dalam mendesain suatu analisis konjoin sebagai berikut,
[1]. Metode konjoin yang mana yang harus dipilih
Pada analisis konjoin setidaknya terdapat 3 (tiga) jenis metode yang dapat dipilih oleh peneliti diantaranya traditional conjoint, adaptive conjoint dan choice-based conjoint. Dimana penentuan pemilihan diantara ketiga metode konjoin yang akan digunakan harus berdasarkan pada beberapa kriteria tertentu diantaranya adalah pada jumlah atribut atau variabel yang disertakan pada model, satuan responden yang akan dianalisis (individu atau kelompok), pemilihan metode analisis pada model dan bentuk dari model konjoin itu sendiri. Untuk mempemudah pemahaman kita, berikut rangkuman metode analisis konjoin berdasarkan kriteria yang mendasarinya,
Gambar 1. Metode dan Kriteria Pemilihan Metode Analisis Konjoin
Dengan pemenuhan tiap kriteria yang menjadi prasyarat yang mendasari metode konjoin yang akan digunakan dapat memandu peneliti atau data master untuk memperoleh output yang optimal dan tepat dari analisis konjoin.
[2]. Bagaimana menentukan variabel atau faktor dengan level-nya di kombinasikan dalam suatu profile
Seperti yang sudah kita ketahui bahwa kesuksesan analisis konjoin diantaranya adalah pada pemilihan dan pengkombinasian faktor beserta level-nya dengan tepat dan yang dapat menggambarkan produk atau jasa tersebut dengan tepat dan jelas. Hal ini sangat penting dikarenakan berpengaruh terhadap keefektifan profile (kombinasi level tiap faktor) dalam tugasnya (menggambarkan produk atau jasa), akurasi pada hasil yang didapat dan utamanya relevan dengan kebutuhan manajerial. Oleh karenya, dalam penentuan faktor berserta level-nya, peneliti harus dapat memastikan 2 (dua) hal bahwa faktor beserta level-nya tersebut dapat dikomunikasikan (communicable) dan dapat diimplementasikan (actionable),
Communicable Measures. “The factor and levels must be easily communicated for a realistic evaluation.” Hal ini menunjukkan kepada kita bahwa kombinasi fitur yang akan dievaluasi kepada konsumen harus sebisa mungkin dapat terkomunikasikan dengan baik kepada konsumen. Hal ini untuk menghindarkan bias pengukuran yang mereflesikan pilihan konsumen. Sebagai contoh, dalam evaluasi parfum atau lotion jika memang dievaluasi berdasarkan format textual tanpa “tester” langsung mungkin tidak mampu menangkap secara sensori beberapa fitur dari produk tersebut, sehingga memungkinkan untuk terjadinya ketidaktepatan dalam pengukuran. Hal-hal seperti itu yang harus dipertimbangkan secara baik oleh peneliti.
Actionable Measures. “The factor and levels also must capable of being put into practice, meaning the attributes must distinct and represent a concept that can be implemented precisely.” Dalam hal ini bahwa atribut yang digunakan untuk menggambarkan produk atau jasa yang diujikan harus mampu dibedakan secara spesifik dan secara kuantitas, tidak tergambarkan secara umum (misal tentang kualitas dan kenyamanan). Hal ini menunjukkan kepada kita bahwa atribut dari produk atau jasa yang diujikan kepada responden harus benar-benar dapat dibedakan satu dengan yang lainnya. Hal ini untuk menghindarkan konsumen dari ketidakpastian dalam memilih suatu atribut dibandingkan dengan atribut lainnya pada produk atau jasa yang diujikan, sehingga hasil yang didapatkan tidak dapat menggambarkan pilihan sebenarnya dari konsumen. Sebagai contoh bahwa pada pada tataran penentuan level dari atribut (mis : kualitas) dihindarkan dari memilih istilah spesifikasi yang kurang tepat, misal : low – moderate – high, dikarenakan hal tersebut bersifat subjektif dan memiliki standar yang berbeda-beda dari tiap konsumen dari pemaknaan yang sebenarnya. Oleh karenanya, pemilihan atribut dan level-nya sebisa mungkin yang dapat membedakan satu sama lain dan begitu pula pada kenyataanya (situasi riil).
Selainkedua hal tersebut di atas, yang harus peneliti perhatikan terkait dengan faktor dan level-nya, ada hal-hal lain yang secara spesifik perlu diperhatikan khusus pada Faktor dan Level-nya.
Faktor. Terdapat setidaknya 3 (tiga) hal yang perlu diperhatikan peneliti dalam hal penentuan faktor diantaranya, jumlah faktor yang akan disertakan (Minimum Profil = Total Level dari Semua Faktor – Jumlah Faktor + 1), multikolinearitas yang mungkin terjadi antar faktor (solusinya dengan memadukan faktor “superattribute” dengan tetap menjaga “actionable” dan “specific”) dan peran unik jika “harga” dijadikan faktor (faktor “harga” sangat berkorelasi dengan banyak faktor lainnya, “harga” merepresentasikan nilai kegunaan produk atau jasa dan “harga” mungkin berinteraksi dengan faktor lainnya, semisal “merk”, oleh karenanya diperlukan perlakuan khusus jika faktor “harga” dimasukan ke dalam analisis konjoin).
Level. Penspesifikan level (level faktor) merupakan aspek yang sangat penting dalam analisis konjoin, hal ini dikarenakan level inilah yang dijadikan dasar pengukuran dalam pembentukan profile produk atau jasa yang akan dievaluasi. Oleh karenanya, penelitian menunjukkan bahwa jumlah dari level, keseimbangan dari jumlah level antar faktor dan jarak antar level (levelisasi) dalam suatu faktor memiliki pengaruh yang berbeda dalam hasil evaluasi pada produk atau jasa.
Yang harus diperhatikan oleh peneliti bahwa tahapan penentuan faktor dan penspesifikan faktor (levelisasi) merupakan tahapan yang paling penting. Hal ini dikarenakan sekali faktor dilibatkan dalam pembentukan profile yang dievaluasi oleh konsumen, maka faktor tersebut tidak dapat dihilangkan. Hal ini dikarenakan konsumen selalu mengevaluasi atribut atau profile sebagai suatu set, sehingga apabila menghilangkan suatu atribut atau profile (setelah diujikan kepada konsumen) dapat membuat analisis konjoin menjadi tidak valid.
[3]. Tipe efek seperti apa yang diharapkan oleh peneliti (main effect -additive model dan atau interaction effect)
Setelahpada 2 (dua) poin sebelumnya kita sudah memilih metode dan faktor beserta level-nya dalam rangka mendesain analisis konjoin yang akan dilakukan. Pada langkah selanjutnya masih dalam rangka mendesain analisis konjoin, yaitu menentukan aturan dalam mengkomposisikan faktor berserta level-nya tadi. Pada umumnya aturan tersebut terdapat 2 (dua) macam yaitu “additive model” dan “adding interactive effects”.
“additive model” merupakan aturan komposisi faktor dan level-nya yang paling umum, yaitu mengasumsikan bahwa nilai total preferensi (utility) dari konsumen diperoleh dengan hanya menambahkan semua nilai (bobot) atribut atau level (part-worth) dari profile produk atau jasa yang dievaluasi. Dalam “additive model” setidaknya variansi preferensi (utility) dari konsumen yang dapat dijelaskan oleh model (part – worth) yaitu sebesar 80% s.d 90%.
“adding interactive effects” merupakan aturan komposisi seperti layaknya pada “additive model”, dimana nilai kegunaan (utility) dari produk atau jasa merupakan jumlah dari part-worth atribut atau level dari produk atau jasa, hanya saja dalam “adding interactive effects” ditambahkan part-worth dari kombinasi yang pasti dari atribut atau level tertentu dari produk atau jasa. Hanya saja dengan penambahan interaksi faktor, penambahan variance yang dapat dijelaskan oleh model hanya sekitar 5% s.d 10%, sedangkan dengan penambahan interaksi faktor dapat menambah cukup banyak profile yang harus di evaluasi oleh konsumen.
Kaitannya dengan kedua model faktor dan level-nya tersebut di atas yakni “additive model” dan “adding interactive effects”, maka dalam hubungannya dengan part-worth maka dikenal 3 (tiga) pola hubungan yaitu linear model, quadratic form (ideal model) dan separate part-worth form. (noted : parth-worth serupa dengan nilai taksiran beta pada analisis regresi). Dimana pemilihan model tersebut harus disesuaikan dengan kondisi melalui informasi a priori yang dimiliki maupun pendekatan berdasarkan informasi empiris.
Gambar 2. Tipe Hubungan Faktor dan Level-nya
[4]. Bentukpengukuran (presentasi) seperti apa yang harus digunakan kepada respondensebagai langkah untuk memperoleh data
Tahapan terakhir dalam mendesain analisis konjoin adalah terkait dengan data collecting. Setidaknya ada 3 (tiga) keputusan yang harus dipertimbangkan oleh peneliti terkait dengan pengambilan data untuk keperluan analisis konjoin diantaranya, tipe dari metode presentasi faktor dan level-nya (type of presentation method for the factors), tipe dari variabel respon (type of response variable) dan metode dari pengambilan data (method of data collection).
Choosing a presentation method.
Terdapat 3 (tiga) metode presentasi faktor dan level-nya kepada konsumen dalam proses evaluasi produk atau jasa kaitannya dengan analisis konjoin diantaranya, full-profile method, dimana setiap profile digambarkan secara terpisah dan lebih sering menggunakan kartu profile sebagai alat bantu evaluasi produk atau jasa oleh konsumen. Penilaian terhadap metode ini dapat dilakukan baik itu dengan cara meranking maupun meratingnya. Selain itu penggunaan metode ini disarankan ketika faktor yang dievaluasi maksimal 6 buah faktor. The pairwise combination presentation, dimana pada metode ini melibatkan 2 (dua) profile yang diperbandingkan dengan cara merating yang menunjukkan kekuatan pilihan dari konsumen atas suatu profile dibandingkan dengan lainnya. Biasanya dalam implementasinya faktor atau atribut yang diperbandingkan hanya sebagian-sebagian dalam sekali evaluasi, hal ini dilakukan untuk menyederhanakan proses evaluasi oleh konsumen jika faktor atau atribut yang dievaluasi sangat banyak, dan trade-off presentation, dimana pada metode ini digunakan 2 (dua) faktor atau atribut dalam sekali evaluasi oleh konsumen dengan merangking setiap kombinasi level dari faktor yang diujikan. Sekilas metode ini sangat mudah bagi konsumen dan mudah secara administrasi, karena hanya melibatkan 2 (dua) faktor dalam sekali pengujian. Beberapa keterbatasan dalam metode ini diantaranya karena tiap pengujian hanya terdapat 2 (dua) faktor atau atribut sehingga memperbanyak penilaian bagi konsumen dan hasil pengukuran yang bersifat nonmetric (ordinal). Untuk memperjelas perbandingan ketiga metode tersebut, berikut disajikan gambar yang memperlihatkan ketiga metode tersebut.
Gambar 3. Metode Presentasi Faktor dan Level-nya
Selecting a measure of consumer preference.
Setelah pada bahasan sebelumnya kita sudah memahami desain analisis konjoin hingga tahapan menentukan metode presentasi untuk mengevaluasi profile produk atau jasa kepada konsumen. Pada tahapan ini kita akan coba mempelajari bagaimana menentukan bentuk profile dan cara pengukurannya. Secara prinsip bahwa semakin banyak faktor dan level-nya yang dilibatkan maka akan semakin banyak dan kompleks profile yang akan disodorkan kepada konsumen untuk di evaluasi dan hal ini yang harus dipertimbangkan secara matang oleh peneliti agar apa yang diharapkan dari proses evaluasi oleh konsumen memberikan hasil yang valid.
Sebagai contoh jika kita memiliki 4 (empat) buah faktor dengan 4 (empat) buah level untuk masing-masing faktor, maka setidaknya akan ada 256 profile (4 x 4 x 4 x 4 = 256) yang harus dievaluasi oleh konsumen.
Selain itu perlu dipertimbangkan juga jumlah minimal profile yang diperlukan untuk mendapatkan estimasi atau taksiran part-worth yang relatif stabil dari model yang dihasilkan. (lihat rumus sebelumnya). Dengan ketentuan tersebut maka minimum responden yang diperlukan untuk mengevaluasi profile produk atau jasa adalah PANGKAT (2 atau 3) dari jumlah parameter atau level-nya. Sebagai tambahan, perlu menjadi pertimbangan bagi peneliti, berdasarkan pengalaman menunjukkan bahwa responden dapat menyelesaikan proses evaluasi dan cenderung valid hingga 30 pilihan profile, akan tetapi setelahnya (> 30) hasil dari evaluasinya sedikit meragukan (disebabkan kelelahan atau tidak fokus lagi).
Sebelum kita sampai pada bahasan cara menentukan pengukuran terhadap profile, sebelumnya mari kita coba memahami cara untuk mendisain suatu profile. Sebagai catatan bahwa profile yang kita susun harus memenuhi setidaknya 2 (dua) aturan diantaranya profile yang disusun memnuhi aturan orthogonality (tidak ada korelasi antar level) dan balanced design (tiap level dari tiap faktor muncul disetiap kali evaluasi). 2 (dua) pendekatan dalam penyusunan profile diantaranya
Fractional Factorial, merupakan pendekatan yang umum digunakan. Cara kerjanya yaitu dengan mengambil sampel profile dari keseluruhan profile yang mungkin, dengan jumlah profile yang digunakan tergantung pada aturan komposisi yang digunakan oleh responden (additive atau adding interactive). Sebagai contoh, dengan menggunakan model additive, metode full-profile dengan 4 (empat) faktor dan 4 (empat) level maka hanya diperlukan 16 (enam belas) profile untuk menaksir efek langsung yang orthogonal dan balance. Sedangkan 240 profile lainnya tidak dipilih dalam desain fractional factorial dan hanya digunakan jika dikehendaki penaksiran dengan menambahkan efek interaksi (adding interactive effect).
Bridging Design, digunakan jika jumlah faktor sangat banyak dan adaptive-conjoint tidak dapat digunakan. Prinsipnya adalah membagi faktor yang banyak tadi menjadi beberapa subset faktor yang sesuai. Dan pembentukan profile berdasarkan pada subset faktor yang terbentuk tadi, sehingga responden tidak disodorkan faktor yang banyak tadi dalam satu kemasan profile.
Kita sudah pahami bagaimana cara mendisain profile yang kita perlukan bagi variabel penelitian yang kita miliki. Selanjutnya kita akan mempertimbangkan dengan cara bagaimana variabel penelitian tersebut (profile) diukur atau dinilai oleh konsumen. Setidaknya ada 2 (dua) jenis pengukuran yang dapat digunakan oleh peneliti diantaranya,
Rank-Ordering. Digunakan untuk mendapatkan suatu rangking atas pilihan atau kesukaan terhadap profile produk atau jasa yang dievaluasi oleh konsumen (rangking profile dari paling disukai atau dipilih hingga paling tidak disukai atau dipilih), dimana terdapat 2 (dua) keuntungan utama. Pertama, rank-ordering mungkin lebih reliable karena penggunaan rank-ordering lebih mudah dibandingkan rating dengan ketentuan bahwa jumlah profile yang dievaluasi cukup sedikit (< 20). Kedua, rank-ordering lebih memiliki fleksibilitas untuk digunakan pada metode additive maupun adding-interactive. Akan tetapi rank-ordering pun memiliki kelemahan diantaranya adalah pada masalah pencatatan (administrasi), dikarenakan prosedur rank-ordering dilaksanakan dengan cara mengurutkan kartu profile berdasarkan urutan pilihan atau kesukaan dan prosedur ini hanya memungkinkan dilakukan dengan cara tatap muka langsung (interviewing).
Rating. Dalam rating, ukuran preferensi yang dihasilkan adalah dalam bentuk skala metrik (interval atau rasio). Keuntungannya adalah hasil preferensi mudah untuk didapat, mudah dalam pencatatan (misal : dengan menggunakan email) dan mudah dalam menganalisa hasilnya (misal : dengan menggunakan regresi multivariat). Aturan yang melekat pada rating adalah setidaknya harus terdapat 11 kategori (misal : 0 s.d 10 atau 10 s.d 100 – dalam kelipatan 10) untuk jumlah profile sampai dengan 16 buah profile dan diperluas menjadi 21 kategori untuk jumlah profile lebih dari 16 buah profile.
Untuk memilih diantara kedua tipe pengukuran tersebut di atas haruslah berdasarkan sisi keprakatisan dan pertimbangan konseptual. Dalam penelitian umum menunjukkan bahwa rank-ordering lebih disukai dibandingkan rating meskipun perlu effort yang sebelumnya dijelaskan.
Survey administration.
Tahapan akhir dalam mendesain analisis konjoin adalah melakukan survey dan melakukan pencatatan data. Sebelum masuk pada bagian tersebut, ada baiknya sekilas kita telaah apakah ada ketentuan lebih lengkap atau praktis mengenai sampel yang diperlukan dalam analisis konjoin, meskipun sedikit aturannya kita sudah sebutkan pada pembahasan sebelumnya.
Secara teoritis bahwa analisis konjoin dapat ditaksir dengan hanya seorang konsumen jika konsumen tersebut melakukan serangkaian pengujian preferensi yang cukup lengkap. Hanya saja peneliti tetap dibebankan oleh konsepsi bahwa sampel tersebut harus mewakili populasi. Selain itu kebutuhan terhadap ukuran sampel tersebut juga berhubungan dengan mencerminkan apa hasil preferensi tersebut (misal : purchasing atau market share) dan seberapa akurat hasil prediksi (hasil analisi konjoin) yang dinginkan. Jika berdasarkan pada interval konfidensi yang diharapkan (error rate), maka ukuran sampel sebesar 200 konsumen cukup memberikan margin error yang dapat diterima. Akan tetapi untuk studi yang lebih kecil lingkupnya, ukuran sampel sebesar 50 konsumen cukup baik dalam memberikan kilasan hasil preferensi konsumen. Oleh karenanya, dari gambaran di atas kita dapat menyimpulkan bahwa ukuran sampel untuk analisis konjoin ideal minimal sebesar 200 unit sampel dan minimal 50 unit sampel.
Sedangkan untuk memperoleh data preferensi konsumen atas intrumen yang telah kita susun, umumnya penelitian yang dilakukan kaitannya dengan penggunaan analisis konjoin, sangat memungkinkan menggunakan cara yang sudah sedikit disinggung pada paparansebelumnya yaitu dengan cara wawancara baik itu dengan menggunakan mail (baik itu kuesioner fisik maupun kuesioner via email) maupun dengan menggunakan telepon. Juga seperti yang telah kita ulas pada paparan sebelumnya, bahwa sebisa mungkin profile yang harus di evaluasi oleh konsumen sesedikit mungkin (tetap menjaga key attributes), hal ini disandarkan pada validitas dan reliabilitas hasil yang diharapkan oleh peneliti (noted : 30 profile awal cenderung reliable dan lebih dari 30 profile cenderung meragukan). Hal tersebut setidaknya dapat dijadikan pertimbangan bagi peneliti, data master atau praktisi bidang usaha untuk merencanakan rencana penggunaan analisis konjoin sebaik mungkin agar pemenuhan terhadap tujuan pengembangan produk atau jasa didapatkan secara optimal.
Demikian 2 (dua) tahapan awal sebagai dasar dalam melakukan analisis konjoin. Dengan pemahaman yang baik atas 2 (dua) tahapan tersebut diharapkan dapat membantu mempermudah pemahaman pada tahapan-tahapan selanjutnya. Awal sangat menentukan hasil akhir, begitu kiranya jika kita memahami tahapan yang harus dilalui ketika kita hendak menggunakan analisis konjoin. Setidaknya 2 (dua) tahapan awal yang sudah kita paparkan di atas yaitu mengenai Tujuan Analisis Konjoin dan Mendesain Analisis Konjoin, dapat dijadikan pondasi awal pemahaman terhadap tahapan-tahapan selanjutnya dari analisis konjoin. Salah dalam memahami proses awal tersebut akan membingungkan dalam pengimplemtasian pada riil kasus yang dimiliki oleh peneliti, data master atau praktisi usaha. Pada artikel selanjutnya kita akan sedikit mengulas pembahasan analisis konjoin diantaranya pada tahapan : Asumsi Analisis Konjoin, Menaksir (part-worth) Model Konjoin dan Uji KecocokanModel, Menginterpretasikan Hasil Analisis Konjoin, dan Memvalidasi HasilAnalisis Konjoin. SEMANGAT MEMAHAMI!!!