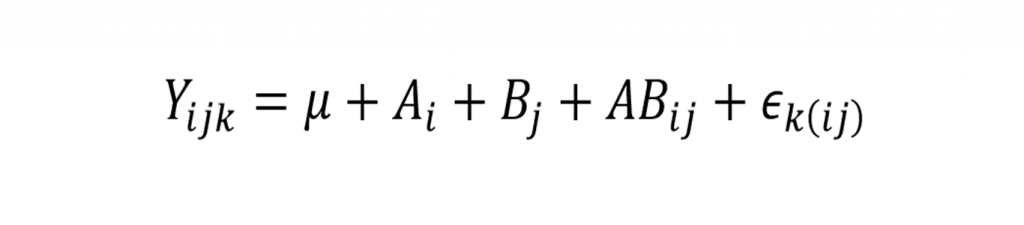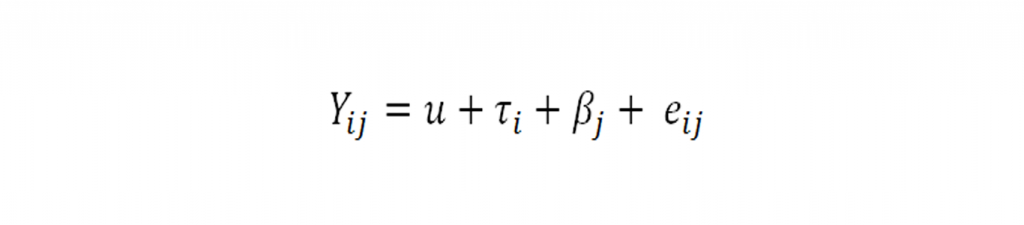Pada artikel terdahulu kita telah membahas dan menguraikan secara singkat dan sederhana mengenai rancangan percobaan faktorial. Sedikit kita ulas kembali bahwa pada rancangan percobaan faktorial kita tidak hanya melibatkan satu perlakuan saja pada unit percobaan (tidak seperti pada RAK dan RAL) melainkan dapat hingga k buah perlakuan. Perlu diperhatikan pula pada percobaan faktorial terdapat unsur efek kombinasi perlakuan, sehingga pada penerapannya pada software SPSS perlu ketelitian untuk menambahkan perhitungan efek kombinasi pada model analisisnya. Sebelum kita membahas pengaplikasian rancangan percobaan faktorial pada SPSS, ada baiknya para peneliti atau data master yang baru saja menemukan artikel ini untuk membaca pula artikel kita tentang Rancangan Percobaan Faktorial.
Lebih lanjut langkah-langkah menggunakan software SPSS pada Rancangan Percobaan Faktorial sebagai berikut.
1. Persiapkan data penelitian yang kita miliki dalam software Microsoft Excel, untuk memudahkan pembacaan pada data, buatlah entry data pengamatan seperti yang sudah kita tunjukkan pada artikel sebelumnya
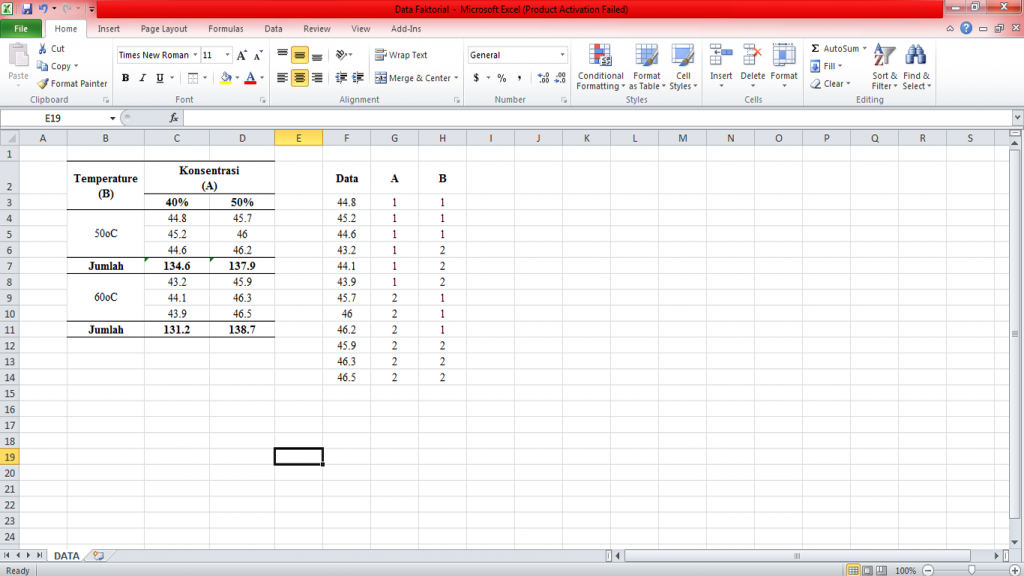
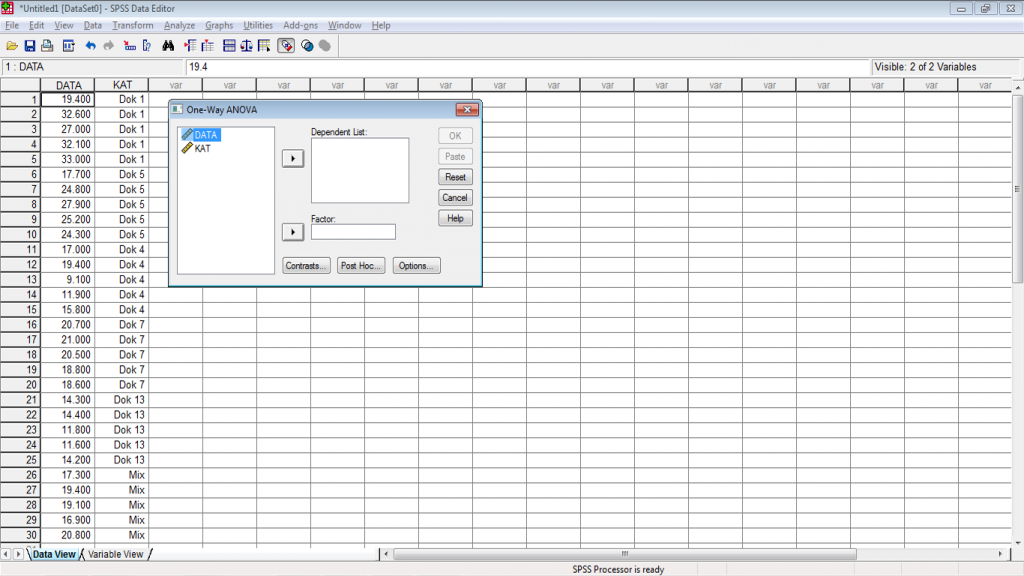
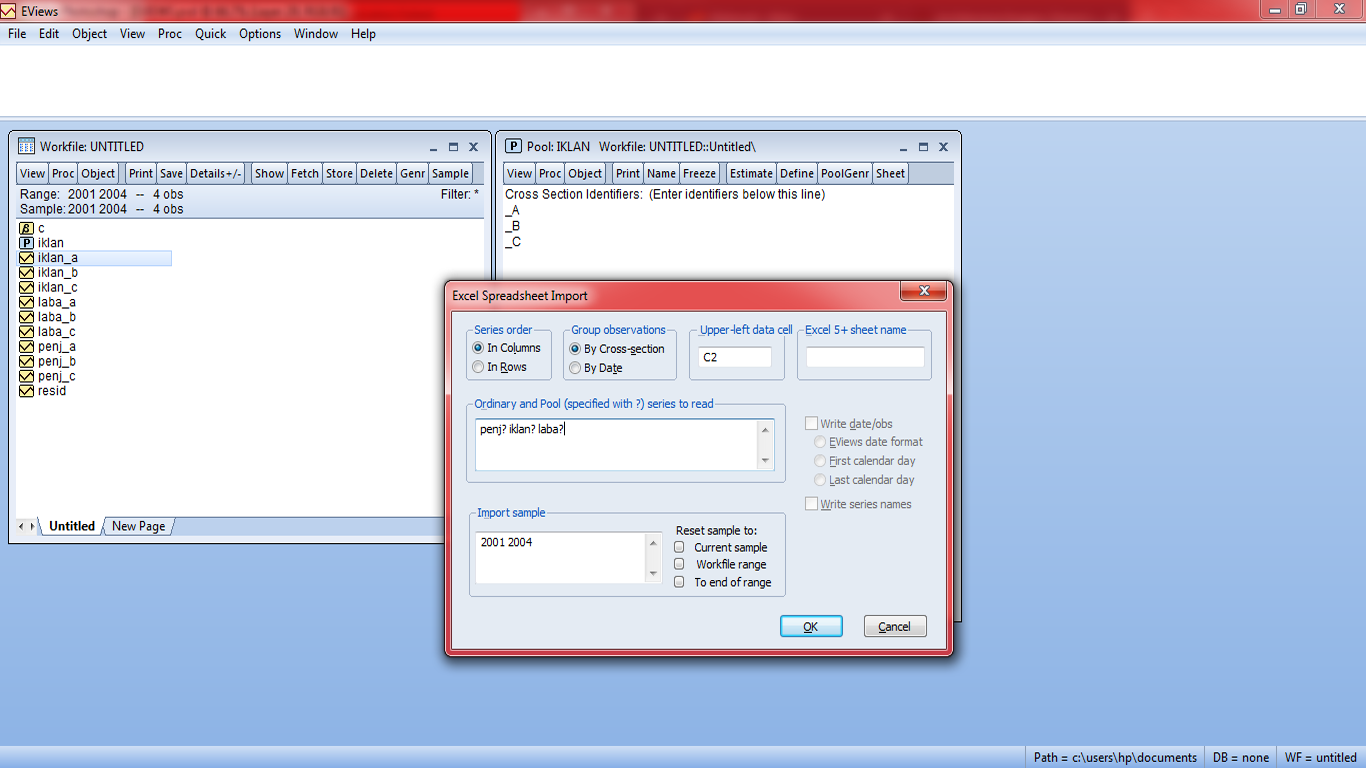
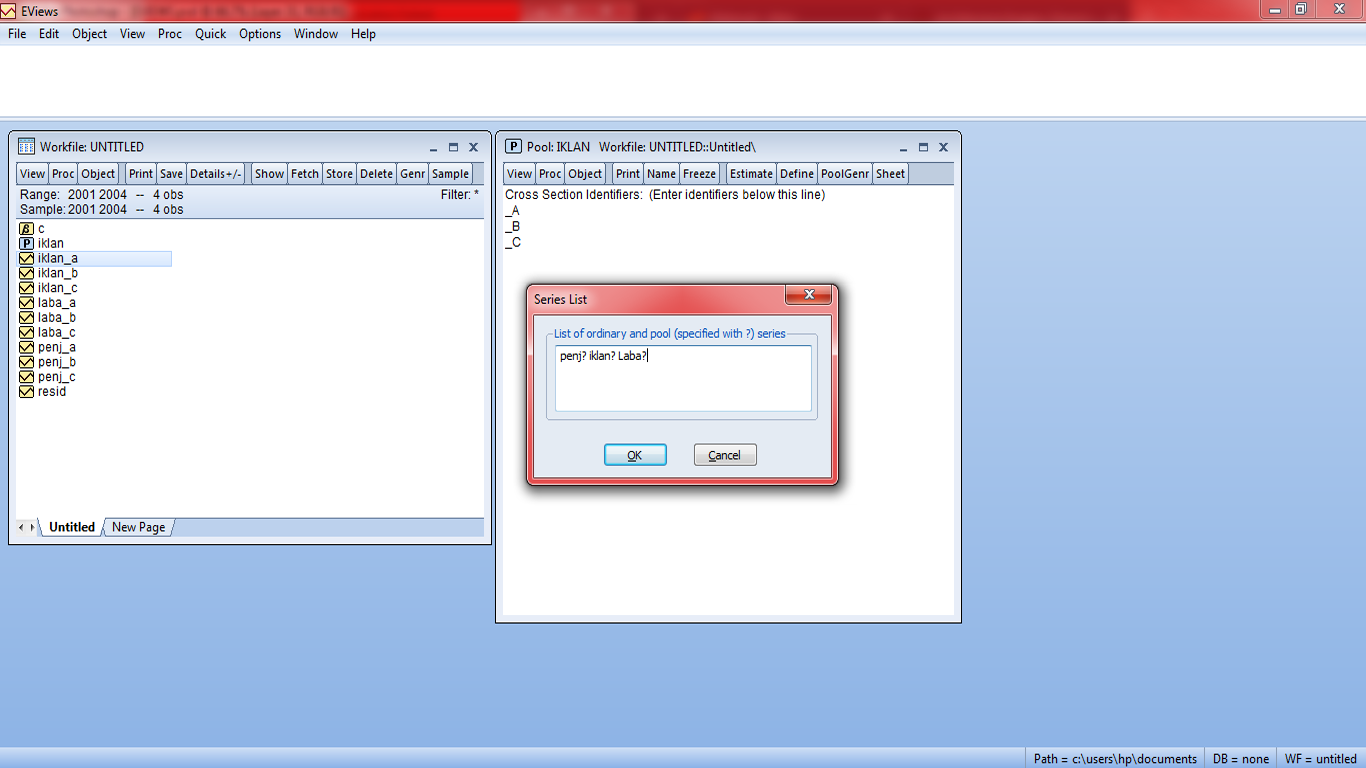
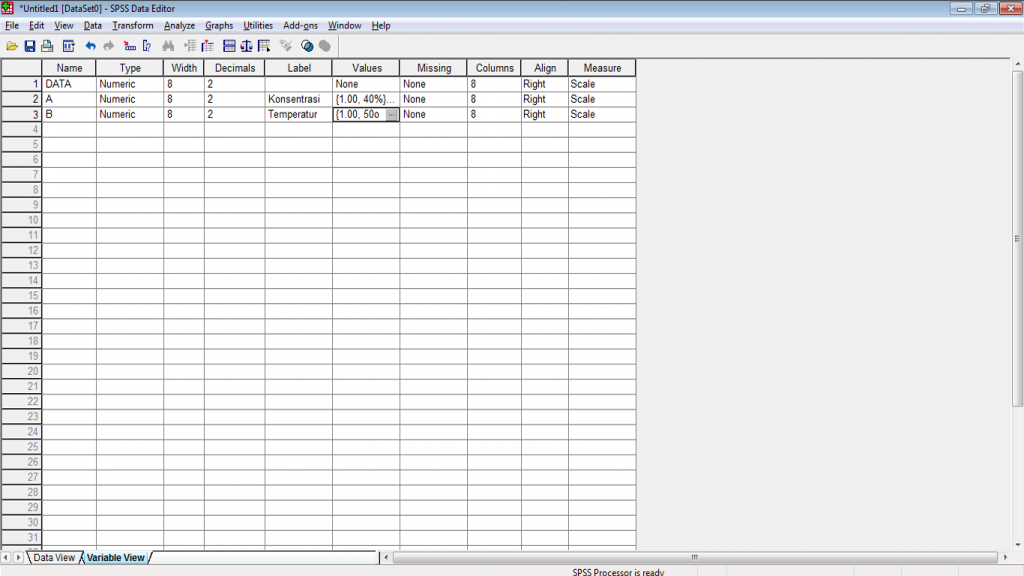
2. Buka software SPSS dan identifikasikan data pada jendela Variabel View, yang terdiri dari tiga jenis variabel yaitu Data Pengamatan [DATA], Kategori Perlakuan [A] dan Kategori Perlakuan [B]. Pengkategorian pada variabel Kategori Perlakuan [A] dan [B] dilakukan dengan cara melakukan koding pada data pada menu Values sesuai dengan kategori perlakuan yang diujikan. Kemudian pada Data View, data pengamatan dijadikan menjadi satu kolom. Tampilan akhir data pada SPSS yang siap untuk dianalisis adalah sebagai berikut.
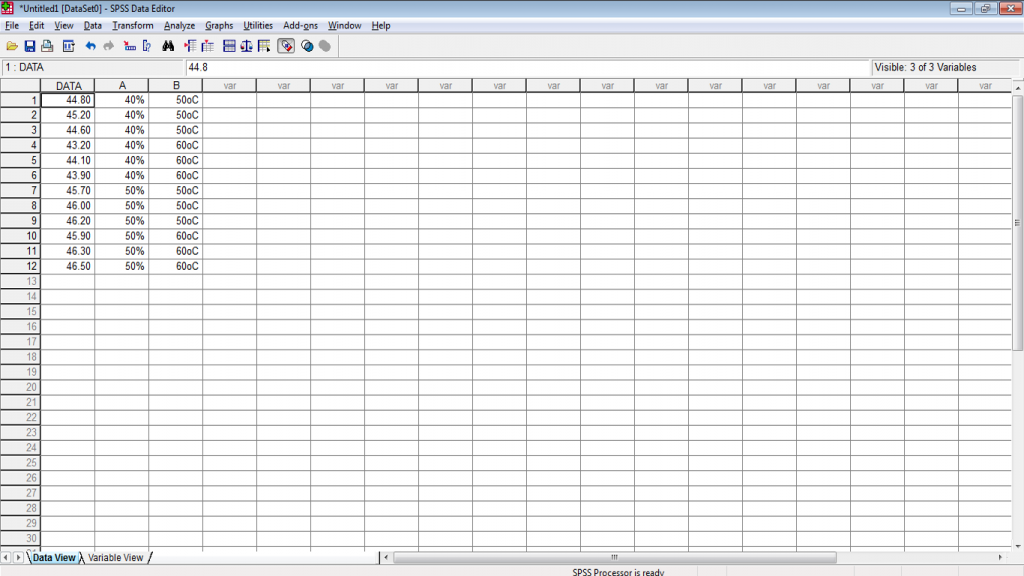
3. Setelah data yang kita miliki siap untuk di analisis, langkah selanjutnya klik menu Analyze lalu pilih pada menu General Linear Model (GLM) lalu klik pada menu Univariate, maka akan muncul tabel sebagai berikut.


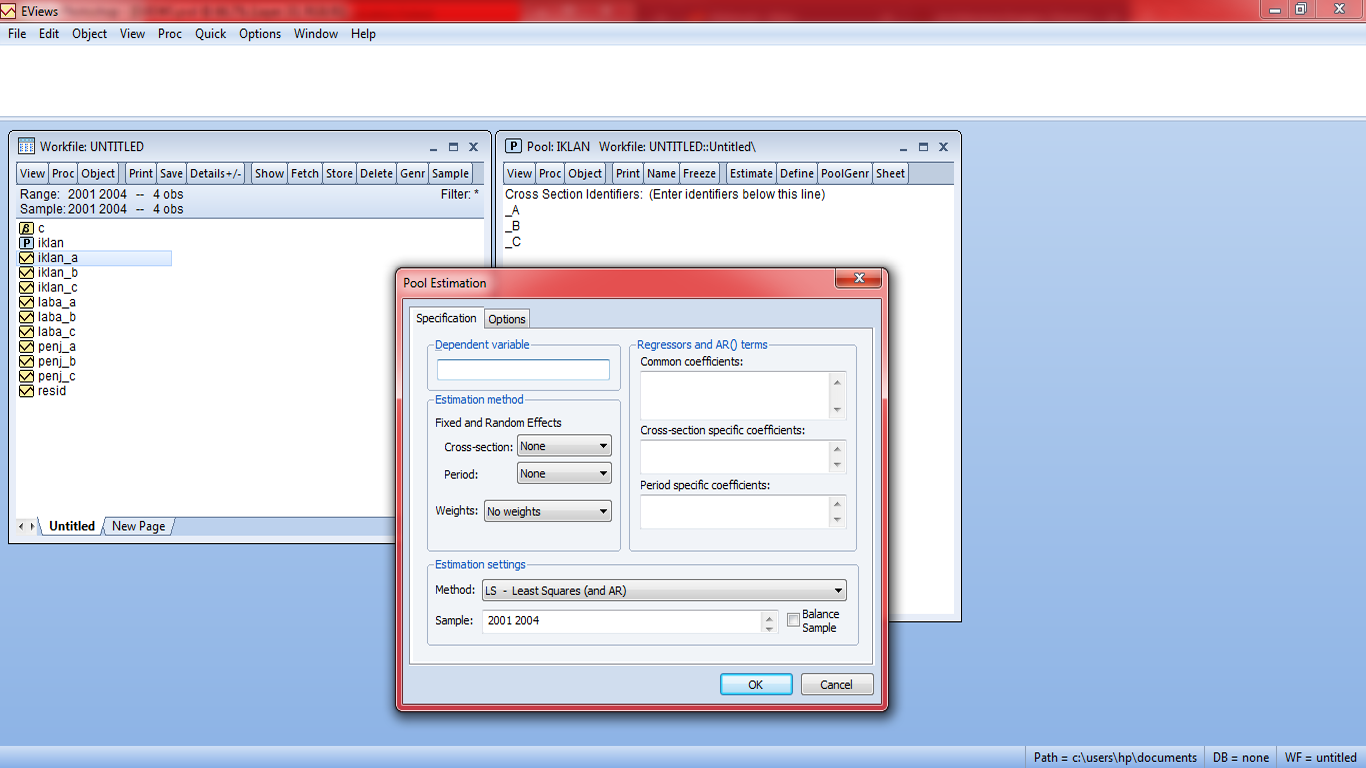
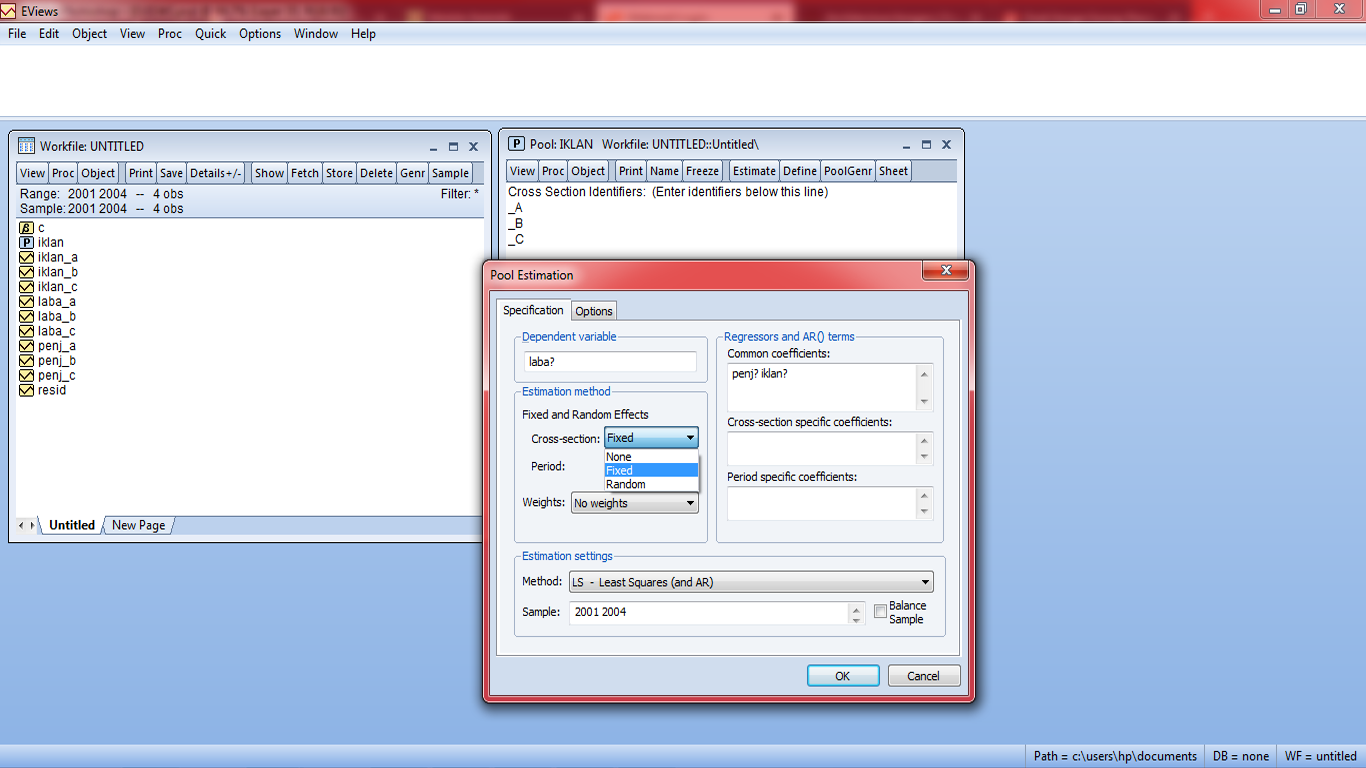
4. Langkah selanjutnya adalah mendefinisikan variabel yang kita miliki pada kolom-kolom yang ada untuk dilakukan analisis pada data. Pertama, isikan pada tabel Dependent Variable variabel yang berisi data hasil pengamatan dan kedua isikan pada tabel Fixed Factor variabel yang berisikan kategori perlakuan yang kita libatkan dalam penelitian, seperti tampak pada gambar berikut. (baca kembali teori pada buku acuan untuk menentukan perlakuan yang kita miliki sebagai Fixed atau Random)

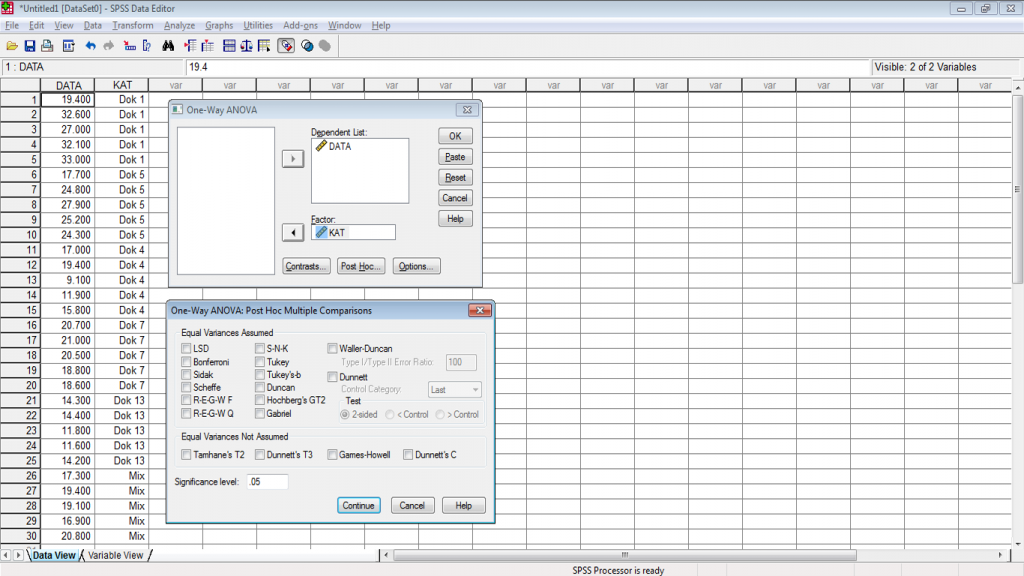
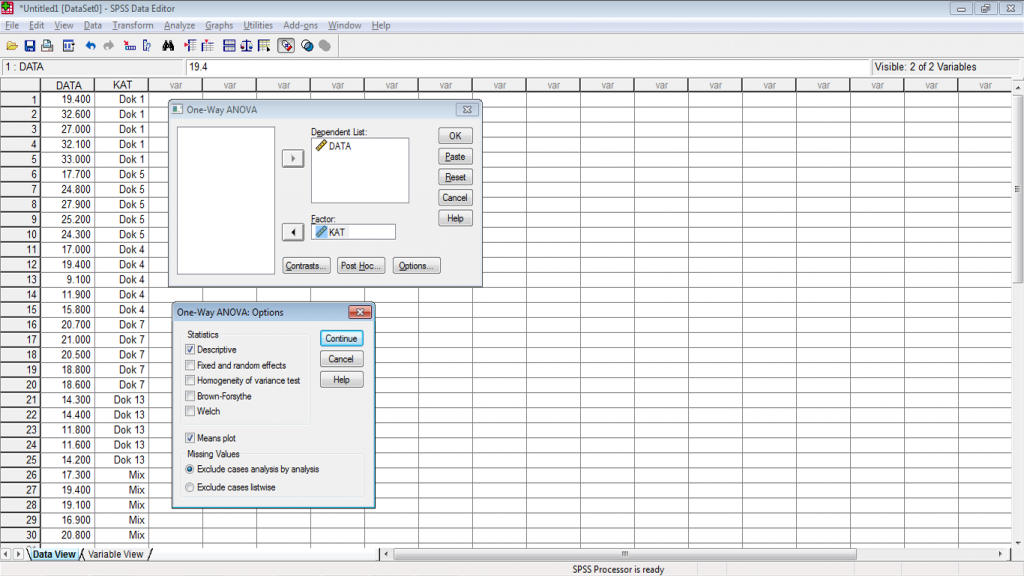
5. Setelah men-set variabel kita dengan tepat sesuai dengan kolom variabelnya, maka langkah selanjutnya adalah mendefinisikan output apa saja yang kita kehendaki, 3 (tiga) menu utama yang sering digunakan adalah Models yang digunakan untuk mendefinisikan model matematis secara teori (main effect dan interaksi) serta metode perhitungan pada Anova, Post Hoc untuk melakukan uji lanjut antar data kelompok perlakuan dan Options untuk memberikan hasil analisis tambahan yang diperlukan dalam rangka interpretasi hasil analisis pada data (noted : untuk jenis analisis tertentu diperlukan teori pendukungnya), seperti tampak pada gambar berikut.


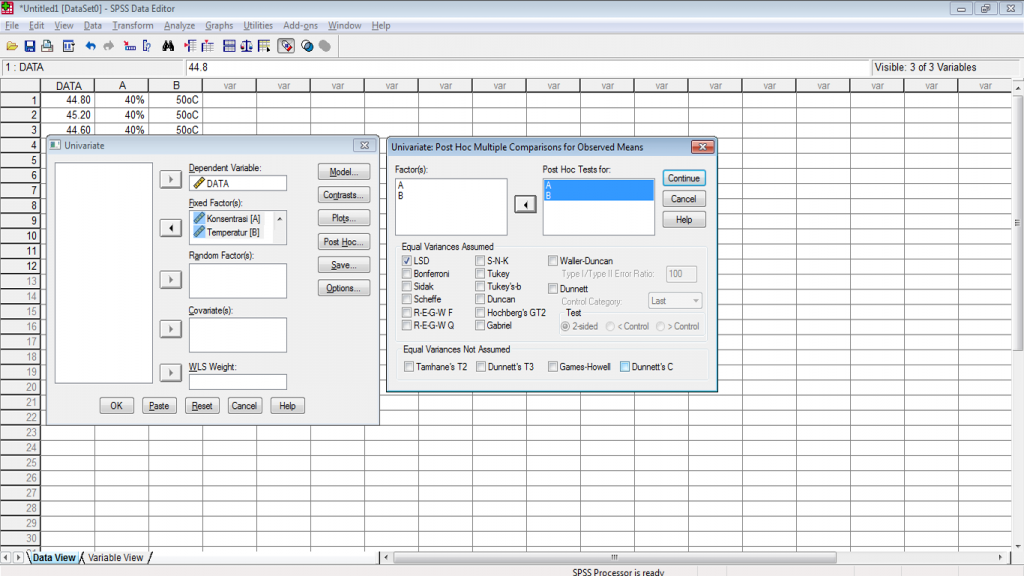
6. Setelah kita yakin dengan data yang kita miliki dan output tambahan yang kita perlukan, setelahnya kita klik OK dan SPSS akan memproses data hasil Rancangan Percobaan Faktorial kita. Output yang dihasilkan dari data Rancangan Percobaan Faktorial yang kita inputkan akan tampak seperti gambar berikut.

Sekilas tahapan yang dilakukan mirip atau hampir sama dengan langkah yang dilakukan untuk menguji data pada Rancangan Acak Kelompok (RAK). Yang perlu diperhatikan dan dipahami oleh peneliti atau data master adalah ciri pada “interaksi antar perlakuan” yang ada pada pengujian rancangan percobaan faktorial sehingga yang dipakai adalah “full faktorial” atau secara manual dapat pula disusun pada menu custom dengan menyertakan pula interaksi perlakuan. Oleh karenanya yang paling penting adalah pemahaman peneliti atau data master bahwa pada rancangan percobaan faktorial selalu dipertimbangkan efek interaksi dari perlakuan yang diujikan.
Sedangkan pada rancangan acak kelompok (RAK) hanya dipertimbangkan levelisasi atau kategorisasi pada unit pengamatan (kelompok pengamatan) dan perlakuan yang dikenakan terhadap unit pengamatan hanyalah perlakuan tunggal. Jadi terdapat perbedaan mendasar yang harus dipahami oleh para peneliti atau data master agar tidak menimbulkan kebingungan ketika pengaplikasian data pada software SPSS.
Sekali lagi, yang menjadi perhatian penulis adalah penguasaan teori tentang Rancangan Percobaan Faktorial yang telah kita uraikan pada artikel sebelumnya sebelum mengaplikasikan pada software SPSS. SEMANGAT MENCOBA!!.
——————————————————————————————————————————————————————————
Jika rekan peneliti memerlukan bantuan Survey Lapangan, Survey Online ataupun Olah Data dapat menghubungi mobilestatistik.com di :
- WhatsApp : 081321709749
- Email : welcome@mobilestatistik.com
Klik “Konsultasi Gratis” untuk mendapatkan informasi atau solusi terkait dengan pertanyaan-pertanyaan seputar metodologi penelitian.
——————————————————————————————————————————————————————————