Pada artikel sebelum kita sudah membahas terkait dengan makna dan arti stasioneritas, penjelasan kita pada stasioner dimudahkan dengan metode grafik dengan harapan bahwa peneliti dapat mencermati kriteria dan spesifikasi pola grafik yang mencirikan dari jenis gangguan stasioner pada data deret waktu yang dimiliki oleh peneliti. Secara umum seperti yang sudah kita jelaskan pada artikel sebelumnya bahwa sedikitnya ada 3 gangguan pada kestasioneran data yaitu ketidakstasioneran pada rata-rata hitung, ketidakstasioneran pada varians serta ketidak stasioneran pada rata-rata hitung dan varians.
Pada kesempatan kali ini kita akan menunjukkan dengan menggunakan SPSS bagaimana mengindentifikasi stasioneritas dengan metode grafik yang sudah dijelaskan sebelumnya. 2 (dua) yang sudah kita jelaskan sebelumnya adalah cara mendapatkan korelogram ACF dan PACF pada bahasan Autokorelasi dan Autokorelasi Parsial. Berikut tahapan dalam SPSS untuk mengidentifikasi ke stasioneran pada data deret waktu :
Persiapkan data yang akan di analisis dalam file excel, untuk memudahkan dalam melakukan persiapan data yang akan dianalisis pada software Pastikan data yang kita miliki merupakan data waktu, seperti tampak pada gambar berikut.
Buka software SPSS, lalu entry-kan data yang sudah kita persipakan pada file excel ke dalam jendela Data View pada SPSS dan lakukan penamaan pada jendela Variabel View pada SPSS, sehingga tampak seperti gambar berikut.
Setelah selesai dengan pendefinisian data, lalu klik Analyse, pilih menu Time Series, lalu muncul menu baru klik pada Sequence Charts, seperti tampak pada gambar berikut.
Pada tampilan menu Squence Charts, untuk tahap awal pengidentifikasian data biarkan default apa yang sudah muncul pada menu Squence Charts, lalu klik OK. Maka proses pembuatan peta data atas waktu dilakukan oleh SPSS.
Pemrosesan oleh SPSS akan dihasilkan output SPSS seperti gambar berikut. Menunjukkan peta data atas waktu yang dapat peneliti amati secara kasa mata untuk memutuskan data yang dimiliki sudah stasioner ataukah belum (baca artikel : Stasioneritas Data Deret Waktu).
Pada hasil output SPSS di atas, peta data atas waktu memperlihatkan pola trend yang hampir mendatar (sejajar sumbu waktu) dan variasi data terletak pada sebuah “pita yang meliput tidak seimbang” trend data, hal ini mengindikasikan bahwa data stasioner lemah dalam rata-rata hitung, tetapi tidak stasioner dalam varians.
Pada korelogram yang dihasilkan pada pembahasan sebelumnya (baca artikel : Autokorelasi dan Autokorelasi Parsial Dengan SPSS). Seperti pada output SPSS berikut.
Gambar 1. Korelogram ACF
Gambar 2. Korelogram PACF
Ketidakstasioneran dalam varians jelas terlihat pada gambar ACF dan PACF-nya, seperti ditunjukkan pada output SPSS di atas, yang keduanya menyajikan pola hampir alternating. Untuk memperjelas pendapat tersebut, perlu dicoba untuk melakukan diferensi orde-1 dari data deret waktu yang dimiliki.
Differencing Orde-1
Kembali pada tampilan menu Squence Charts, untuk tahap lanjutan pengidentifikasian data, centang pada menu Transform pilih/centang Difference lalu isikan nilai 1 (satu), seperti terlihat pada gambar berikut, lalu klik OK. Maka proses pembuatan peta data atas waktu dengan differensi orde-1 dilakukan oleh SPSS.
Pemrosesan oleh SPSS akan dihasilkan output SPSS seperti gambar berikut. Menunjukkan peta data atas waktu hasil differensi orde-1 yang dapat peneliti amati secara kasat mata untuk memutuskan data yang dimiliki sudah stasioner ataukah belum (baca artikel : Stasioneritas Data Deret Waktu).
Pada hasil output SPSS di atas, peta data atas waktu dengan differensi orde-1 memperlihatkan pola data dengan trend mendatar dan pola “terompet di sisi kiri dan kanan”, hal ini mengindikasikan bahwa dengan diferensi orde-1 data yang tadinya stasioner lemah dalam rata-rata hitung menjadi stasioner kuat dalam rata-rata hitung.
Selanjutnya untuk menghasilkan korelogram orede-1, pada tampilan menu Autocorrelation, centang pada menu Transform pilih/centang Difference lalu isikan nilai 1 (satu), seperti terlihat pada gambar berikut, lalu klik OK. Maka proses penghitungan nilai Autokorelasi dan Autokorelasi Parsial dilakukan oleh SPSS.
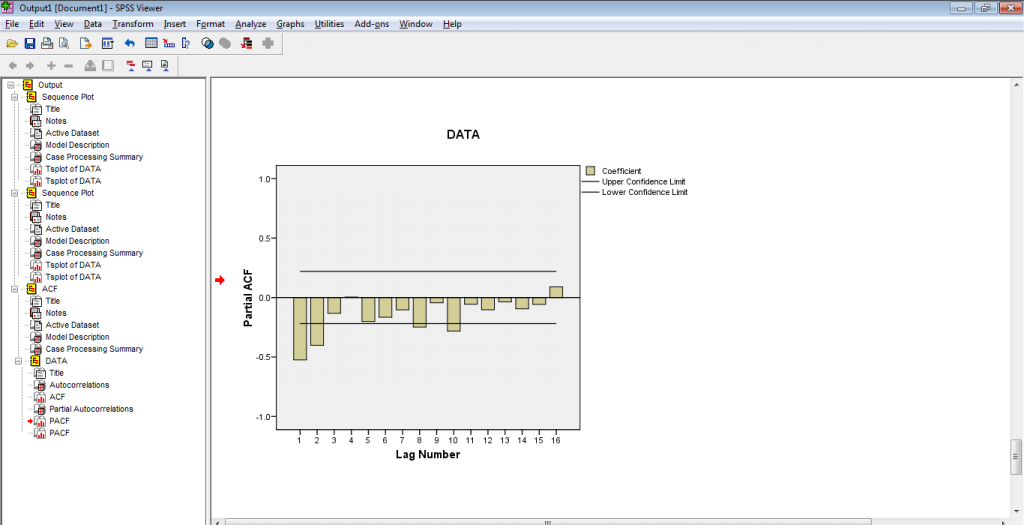
Pemrosesan oleh SPSS akan dihasilkan output SPSS seperti gambar berikut. Menunjukkan korelogram ACF dan PACF hasil differensi orde-1 yang dapat peneliti amati secara kasa mata untuk memutuskan data yang dimiliki sudah stasioner ataukah belum (baca artikel : Stasioneritas Data Deret Waktu)
Gambar 1. Korelogram ACF Differensi Orde-1
Gambar 2. Korelogram PACF Differensi Orde-1
Pada hasil output SPSS di atas, korelogram ACF yang membangun pola alternating dan korelogram PACF membangun pola “hampir gelombang”, hal ini menunjukkan bahwa proses diferensi belum bisa menstabilkan varians, tetapi tidak perlu dilakukan lagi diferensi (cukup orde-1), yang harus dilakukan adalah transformasi stabilitas varians.
Butuh efforts yang ekstra untuk menemukan bentukan data deret waktu yang ideal untuk dibentuk menjadi sebuah model matematis yang baik untuk digunakan dalam peramalan. Pada kesempatan lain, kita akan bahas beberapa metode penghalusan (smoothing) yang digunakan untuk mendapatkan data yang sesuai (salah satunya memenuhi kriteria stasioneritas) untuk membentuk model regesi data deret waktu yang ideal untuk peramalan. SEMANGAT MENCOBA!!!
Pada kesempatan kali ini kita akan sedikit mengupas apa itu makna atau arti dari stasioneritas dari data deret waktu. Uraian pada artikel sebelumnya sudah sedikit disebutkan bahwa dalam analisis data deret waktu, dua asumsi yang perlu diperhatikan adalah adanya autokorelasi pada data deret waktu dan data deret waktu yang dimiliki adalah data yang stasioner. Karena merupakan asumsi bagi kesempurnaan model data deret waktu yang dihasilkan nantinya, maka pemahaman akan makna atau arti kestasioneran tersebut patut mendapatkan perhatian serius juga oleh peneliti.
Stasioneritas
Kestasioneran data merupakan kondisi yang diperlukan dalam analisis regresi deret waktu karena dapat memperkecil kekeliruan model, sehingga jika data tidak stasioner, maka harus dilakukan transformasi stasioneritas melalui proses diferensi, jika trend-nya linier, sedangkan jika tidak linier, maka transformasi linieritas trend melalui proses logaritma natural jika trend-nya eksponensial, dan proses pembobotan (penghalusan eksponensial sederhana) jika bentuknya yang lain, yang selanjutnya dilakukan proses diferensi pada data hasil proses linieritas.
Berdasarkan deskripsinya, bentuk kestasioneran ada dua yaitu Stasioner Kuat (Strickly Stationer) atau Stasioner Orde Pertama (Primary Stationer) dan stasioner lemah (Weakly Stationer) atau Stasioner orde kedua (Secondary Stationer). Deskripsi umum kestasioneran adalah sebagai berikut, Xt1, Xt2, … disebut stasioner kuat jika distribusi gabungan Xt1, Xt2, … , Xtn sama dengan distribusi gabungan Xt1+k, Xt2+k, … , Xtn+k, untuk setiap nilai t1, t2, … , tn dan k. Sedangkan disebut stasioner lemah, jika rata-rata hitung data konstan, E(X) = µ dan autokovarians-nya merupakan fungsi dari lag ρk = f(k). Sedangkan ketidaksioneran data diklasifikasikan atas 3 (tiga) bentuk yaitu :
Tidak stasioner dalam rata-rata hitung, jika trend tidak datar (tidak sejajar sumbu waktu) dan data tersebar pada “pita” yang meliputi secara seimbang trendnya.
Tidak stasioner dalam varians, jika trend datar atau hampir datar tapi data tersebar membangun pola melebar atau menyempit yang meliputi secara seimbang trendnya (pola terompet).
Tidak stasioner dalam rata-rata hitung dan varians, jika trend tidak datar dan data membangun pola terompet.
Identifikasi Ke-tidak-stasioner-an Data Deret Waktu
Untuk menelaah ketidak-stasioneran data secara visual, tahap pertama dapat dilakukan pada peta data atas waktu, karena biasanya “mudah” dan jika belum mendapatkan kejelasan, maka tahap berikutnya ditelaah pada gambar ACF dan PACF. Telaahan pada gambar pada peta data atas waktu, ACF dan PACF, jika data tidak stasioner maka gambarnya akan membangun pola diantaranya :
Menurun, jika data tidak stasioner dalam rata-rata hitung (trend naik atau turun).
Gambar 1. Data tidak stasioner dalam rata-rata hitung
Gambar 2. ACF data tidak stasioner dalam rata-rata hitung
Gambar 3. PACF data tidak stasioner dalam rata-rata hitung
Alternating, jika data tidak stasioner dalam varians.
Gambar 1. Data tidak stasioner dalam varians
Gambar 2. ACF data tidak stasioner dalam varians
Gambar 3. PACF data tidak stasioner dalam varians
Gelombang, jika data tidak stasioner dalam rata-rata hitung dan varians.
Gambar 1. Data tidak stasioner dalam rata-rata hitung dan varians
Gambar 2. ACF data tidak stasioner dalam rata-rata hitung dan varians
Gambar 3. PACF data tidak stasioner dalam rata-rata hitung dan varians
Dari beberpa penjelasan secara visual di atas, baik itu dari sisi peta data atas waktu, korelogram ACF dan PACF kiranya dapat memudahkan pemahaman bagi peneliti terkait perbedaan antar jenis ketidaksioneran yang terjadi pada data. Sehingga pada akhirnya dapat menuntun peneliti pada ketepatan treatment atas data yang dimiliki. SEMANGAT MEMAHAMI!!!
Pada artikel sebelumnya kita sudah memaparkan bentukan autokorelasi dan autokorelasi parsial yang terbentuk pada data deret waktu. Fungsi atau kegunaan yang sudah kita paparkan diantaranya adalah untuk melihat signifikansi autokorelasi yang dihasilkan data sebagai prasyarat dari analisis deret waktu dan juga berfungsi dalam mendeteksi kestasioneran data yang dimiliki. Salah satu diantaranya dengan melihat korelogram.
Pada kesempatan kali ini akan coba kita uraikan tahapan penggunaan software SPSS untuk menghasilkan korelogram, yang dibutuhkan dalam penilaian awal atas data deret waktu yang digunakan dalam analisis. Tahapannya adalah sebagai berikut :
Persiapkan data yang akan di analisis dalam file excel, untuk memudahkan dalam melakukan persiapan data yang akan dianalisis pada software Pastikan data yang kita miliki merupakan data waktu, seperti tampak pada gambar berikut.
Buka software SPSS, lalu entry-kan data yang sudah kita persipakan pada file excel ke dalam jendela Data View pada SPSS dan lakukan penamaan pada jendela Variabel View pada SPSS, sehingga tampak seperti gambar berikut.
Setelah selesai dengan pendefinisian data, lalu klik Analyse, pilih menu Time Series, lalu muncul menu baru klik pada Autocorrelation, seperti tampak pada gambar berikut.
Pada tampilan menu Autocorrelation, sudah default pada menu Display,Autocorrelation dan PartialAutocorrelation akan tercentang (biarkan, karena yang akan dianalisis adalah autokorelasi pada data). Untuk tahap awal pengidentifikasian data biarkan default apa yang sudah muncul pada menu Autocorrelation, lalu klik OK. Maka proses penghitungan nilai Autokorelasi dan Autokorelasi Parsial dilakukan oleh SPSS.
Pemrosesan oleh SPSS akan dihasilkan output SPSS seperti gambar berikut. Terdapat 4 bagian utama sebagai mana dijelaskan pada artikel sebelumnya yaitu nilai Autokorelasi, korelogram ACF, nilai Autokorelasi Parsial dan korelogram PACF.
Gambar 1. Nilai Autokorelasi Berdasarkan Lag-k
Gambar 2. Diagram ACF Fungsi Autokorelasi
Gambar 3. Nilai Autokorelasi Parsial Berdasarkan Lag-k
Gambar 4. Diagram PACF Fungsi Autokorelasi Parsial
Jika ditelaah, gambar ACF dan PACF keduanya membangun pola alternating (tanda dan nilai autokorelasi berubah secara acak sesuai dengan berjalannya nilai lag), hal ini mengindikasikan data tidak stasioner dalam varians dan stasioner lemah dalam rata-rata hitung. Sedangkan signifikansi autokorelasi kemungkinannya lemah (nilai lag-nya cukup besar jika dibandingkan dengan ukuran sampelnya). Jika hasil telaahan secara “visual” tidak cukup menyakinkan, maka dapat dilakukan pengujian hipotesis statistis untuk keberartian autokorelasi.
Dengan adanya SPSS sebagai software yang sangat mudah untuk digunakan oleh peneliti, dapat membantu dalam mempercepat dalam pemrosesan data. Hal yang perlu diperhatikan oleh peneliti adalah pemahaman akan teori atau konsep yang mendasari penggunaan tools statistik dalam SPSS itu sendiri. Secara tampilan SPSS memperlihatkan menu-menu berdasarkan konsep tools statistik yang ada pada teori yang melatarbelakanginya, jadi alangkah baiknya dan tepat apabila sebelum mengaplikasikan data pada SPSS dibangun kepahaman secara menyeluruh atas teori pada tools statistik yang akan dipakai oleh peneliti. SEMANGAT MENCOBA!!!
Pada artikel sebelumnya kita sudah mengenal apa itu analisis regresi deret waktu, tahapan-tahapan analisis serta kegunaan analisis deret waktu itu sendiri. Salah satu asumsi yang harus dipenuhi dan layak sebuah deret data dilakukan analisis regresi deret waktu adalah adanya autokorelasi antar pengamatan (korelasi dalam variabel respon Y).
Pada kesempatan kali ini kita akan menjelaskan peran autokorelasi dalam analisis deret waktu, yang kita hadapi dalam analisis deret waktu terdapat dua jenis korelasi yaitu autokorelasi dan autokorelasi parsial. Apa arti dan kegunaan dua jenis korelasi tadi dalam analisis regresi deret waktu akan dipaparkan pada penjelasan berikut.
Autokorelasi
Konsepsi autokorelasi setara (identik) dengan korelasi Pearson untuk data bivariat. Gambarannya sebagai berikut, jika dimiliki sampel data deret waktu X1, X2, … , Xn dan dapat dibangun pasangan nilai (X1, Xk+1), (X2, Xk+2), …, (Xk, Xn). Dalam analisis data deret waktu untuk mendapatkan hasil yang baik, nilai n harus cukup besar dan autokorelasi disebut berarti jika nilai k cukup kecil dibandingkan dengan n, sehingga autokorelasi lag-k dari sampel data deret waktu yang terbentuk adalah
Dan perumusan autokoerelasi seperti di atas digunakan dalam analisis data deret waktu. Karena rk merupakan fungsi atas k, maka hubungan autokorelasi dengan lag-nya dinamakan Fungsi Autokorelasi (Autocorrelation Function, ACF) dan dinotasikan oleh ρ(k).
Autokorelasi Parsial
Konsepsi lain pada autokorelasi adalah autokorelasi parsial (partial autocorrelation), yaitu korelasi antara Xt dengan Xt+k, dengan mengabaikan ketidakbebasan Xt+1, Xt+2, … , Xt+k-1, sehingga Xt dianggap sebagai konstanta, Xt = xt , t = t+1, t+2, … , t+k-1. Autokkorelasi parsial Xt dengan Xt+k didefinisikan sebagai korelasi bersyarat,
Seperti halnya autokorelasi yang merupakan fungsi atas lagnya, yang hubungannya dinamakan fungsi autokorelasi (ACF), autokorelasi parsial juga merupakan fungsi atas lag-nya dan hubungannya dinamakan Fungsi Autokorelasi Parsial (Partial Autocorrelation Function, PACF).
Untuk menghitung autokorelasi dan autokorelasi parsial banyak kemasan program (software) komputer yang dapat digunakan, seperti SPSS, MINITAB, dan STATISTICA, sehingga jika para pengguna analisis data deret waktu tidak memahami konsepsi perhitungan dan pembuatan program komputer untuk perhitungannya, bisa menggunakan salah satu kemasan program tersebut untuk keperluan analisisnya. Pada artikel selanjutnya kita akan bahas penggunaan software SPSS dalam menghasilkan ACF dan PACF dalam grafik korelogram yang salah satunya dapat membantu peneliti dalam mengidentifikasi kebaikan model data deret waktu yang terbentuk. SEMANGAT MEMPELAJARI!!!
Pada kesempatan kali ini kita akan sharing pengalaman kita di lapangan, survey lapangan atau sebar kuesioner, yang berbeda dengan sharing pada kesempatan sebelumnya. Survey lapangan atau sebar kuesioner kali ini, hendak menggali informasi atau perspektif dari pengurus ORMAS di Kota Bandung, tepatnya informasi atau perspektif para pengurus ORMAS dalam hal penggunaan situs aplikasi online bansos dan hibah Sabilulungan Kota Bandung. Sekali lagi bahwa persiapan fisik maupun pengetahuan terhadap medan lapangan yang akan dijadikan sasaran pengambilan data haruslah diperhatikan. Karena banyak hal-hal yang tidak bisa kita prediksikan dapat terjadi dan menjadi tantangan tersendiri di lapangan.
Objek dari survey lapangan atau sebar kuesioner lapangan kali ini dalam kategori gampang-gampang susah. Target spesifik yang menjadi kriteria dari responden adalah pengurus ORMAS di Kota Bandung yang pernah meng-akses atau menggunakan situs aplikasi online bansos dan hibah Sabilulungan Kota Bandung. Kategori gampang-gampang susah di sini, “gampang” karena merupakan organisasi non pemerintah sehingga prosedural birokrasi relatif bisa diabaikan dan “susah” karena organisasi bentukan masyarakat, hunting untuk mendapatkan lokasi target sampel butuh perjuangan luar biasa (menyusuri gang-gang dan lokasi yang tidak dapat ditemukan GPS sekalipun).
Sebagai alternatif, penggunaan form online sebagai cara pendukung cukup membantu dalam proses pengambilan data, meskipun tantangan sebagai “strangger” kendala terbesar dalam mendapatkan respon dari responden sehingga uncertainty menjadi kendala terbesar lainnya dalam proses online survey.
Crew lapangan yang diturunkan pada survey lapangan kali ini sebanyak 1 orang di bantu dengan tim office untuk survey online. Crew yang well educated, bermental OK, PeDe, memiliki komunikasi yang baik dan behave yang menyenangkan bagi responden. Karena yang kita temui dilapangan adalah para aktivis masyarakat yang memiliki massa dan wibawa. So, right person is a must.
Proses survey yang sangat challenging yang tim kita temui di lapangan, wellplanning dan well strategy dalam melakukan survey lapangan kali ini sangat diperlukan sekali, sekali lagi cost and time effective dalam penelitian. Calon responden yang kita hadapi adalah responden memiliki kecenderungan untuk menolak sangat tinggi dikarenakan frame bermanfaatnya research dan issue yang dibawa relatif sensitif, bansos dan hibah. Selain itu, dikarenakan usia ORMAS boleh jadi sudah cukup berusia sehingga tidak sedikit pengurus ormas yang merupakan generasi “sepuh” sehingga pengetahuan terhadap teknologi yang sifatnya internet hingga aplikasi online (web) menjadi tantangan tersendiri.
Hal lain, faktor teknis berupa sosialisasi dari pihak pemerintah yang belum sepenuhnya diterima oleh pihak ORMAS (dikarenakan ORMAS hanya wadah sewaktu-waktu untuk beraktifitas) menjadi kendala yang cukup berarti yang ditemui di lapangan yang mengakibatkan calon responden enggan untuk berpartisipasi. Oleh karenanya, tim lapangan kita tidak jarang merangkap fungsi sebagai tim sosialisasi dari tools pemerintah.
Saran kita berdasarkan pengalaman di lapangan diperlukan extra time untuk melakukan penelitian dengan kriteria responden dari organisasi masyarakat (ORMAS) baik kecil atau besar. Rencana time line research yang harus well planning dan well organized. Networking atau Offering Benefits mungkin bisa jadi instrumen yang dapat mempermudah dan mempercepat dalam proses pengambilan data lapangan.
Sharing singkat ini, semoga bermanfaat dalam membantu rekan-rekan peneliti dalam membangun frame awal sebelum melakukan survey di lapangan. Kami akan share banyak pengalaman kami di lapangan pada kesempatan yang lain. SEMANGAT MENELITI!!!
Pada kesempatan kali ini kita akan membahas secara konsepsi terkait dengan data time series beserta konsepsi pemodelan dengan menggunakan data time series. Perlu diperhatikan sebelumnya kepada para peneliti atau pembaca artikel kami, bahwa ada baiknya membaca konsepsi regresi beserta uraian pengujian asumsi regresi linear klasik yang sudah kita bahas pada artikel-artikel sebelumnya. Tidak lain untuk membangun pemahaman secara terstruktur terkait dengan pemodelan, mulai dari yang umum atau kebanyakan peneliti gunakan yaitu analisis regresi. Selain itu, pengembangan pembahasan pada konsepsi Lag (Waktu) juga sudah kita paparkan pada artikel sebelumnya (baca : Distributed Lag Model dan Autoregresif Model) yang diharapkan dapat mempermudah bagi pembaca dalam memahami konsep yang akan dibahas pada kesempatan kali ini.
Pembahasan terkait dengan data deret waktu atau time series jauh berbeda dengan konsepsi yang kita bangun pemahamannya dengan data crossectional dengan analisis regresi. Pada bahasan terkahir pada pemodelan Distributed Lag Model dan Autoregresif Model sudah sedikit bersentuhan dengan konsep waktu pada pemodelan yang dihasilkan meskipun data yang digunakan masih bersifat crossectional dan dikembangan salah satunya didasarkan tidak terpenuhinya asumsi non autokorelasi pada model regresi linear klasik.
Sekarang mari kita jelajahi lebih lengkap terkait dengan analisis data time series pada beberapa artikel kita kedepan.
Data Deret Waktu (Time SeriesData)
Pada dasarnya setiap nilai dari hasil pengamatan (data), selalu dapat dikaitkan dengan waktu pengamatannya. Hanya pada saat analisisnya, kaitan variabel waktu dengan pengamatan sering tidak dipersoalkan. Dalam hal kaitan variabel waktu dengan pengamatan diperhatikan, sehingga data dianggap sebagai fungsi atas waktu, maka data seperti ini dinamakan Data Deret Waktu (Time series).
Karena data deret waktu merupakan regresi data atas waktu, dan salah satu segi (aspect) pada data deret waktu adalah terlibatnya sebuah besaran yang dinamakan Autokorelasi (autocorrelation), yang konsepsinya sama dengan korelasi untuk data bivariat, dalam analisis regresi biasa. Signifikansi (keberartian) autokorelasi menentukan analisis regresi yang harus dilakukan pada data deret waktu. Jika autokorelasi tidak signifikan (dalam kata lain data deret waktu tidak berautokorelasi), maka analisis regresi yang harus dilakukan adalah analisis regresi sederhana biasa, yaitu analisis regresi data atas waktu. Sedangkan jika signifikan (berautokorelasi) harus dilakukan analisis regresi data deret waktu, yaitu analisis regresi antar nilai pengamatan. Segi lain dalam data deret waktu adalah kestasioneran data yang diklasifikasikan atas stasioner kuat (stasioner orde pertama, strickly stationer) dan stasioner lemah (stasioner orde dua, weakly stationer), dan kestasioner ini merupakan kondisi yang diperlukan dalam analisis data deret waktu, karena akan memperkecil kekeliruan baku.
Regresi Deret Waktu
Analisis regresi deret waktu adalah analisis regresi dalam kondisi variabel respon (Y) berautokorelasi, sehingga antar variabel respon (Y) dapat dibangun sebuah hubungan fungsional, yang dalam analisis data deret waktu bentuk hubungannya selalu digunakan regresi linier.
Konsepsi analisis regresi linier biasa dapat digunakan secara utuh dalam analisis regresi deret waktu, hanya proses perhitungan nilai penaksir parameternya tidak selalu bisa dijadikan acuan. Dalam analisis regresi linier biasa, proses perhitungan taksiran parameter selalu dapat dilakukan dengan menggunakan perhitungan matriks, sebab sistem persamaan parameternya selalu merupakan sistem persamaan linier. Sedangkan dalam analisis regresi deret waktu, ada beberapa model yang perhitungan taksiran parameternya harus menggunakan metoda iterasi atau rekursif, sehingga sebagian besar persoalan analisis regresi deret waktu harus diselesaikan dengan menggunakan fasilitas komputer.
Dalam analisis data deret waktu, jika pengamatan berautokorelasi maka model hubungan fungsionalnya dibangun berdasarkan kondisi kestasioneran data, sehingga model regresi deret waktu dikelompokan atas regresi deret waktu stasioner dan regresi deret waktu tidak stasioner. Model regresi deret waktu tidak stasioner identik dengan model regresi deret waktu stasioner, yang terlebih dulu data distasionerkan melalui proses diferensi. Jika data deret waktu Xt , t = 1, 2, . . . berautokorelasi maka model regresi antar pengamatan (autoregresi) disajikan dalam persamaan
dengan Zt kekeliruan model yang diasumsikan berdistribusi identik independen dengan rata-rata 0 dan varians konstan σ2, yang dalam analisis data deret waktu Zt biasa disebut white noise dan µ , γ1 , . . . , γk merupakan parameter autoregresi. Model autoregresi persamaan di atas dinamakan Autoregresi Lag-k dan disingkat AR(k). Dan,
Model persamaan di atas dinamakan model rata-rata bergerak (moving average) order p disingkat MA(p). Jadi dalam model MA(p) merupakan model inversi dari AR(k), yang berarti model AR(k) dan MA(p) merupakan model yang saling berkebalikan.
Model AR(k) dan MA(p) merupakan model regresi deret waktu stasioner dan saling berkebalikan, sehingga keduanya dapat digabungkan dengan cara dijumlahkan, dan model yang diperoleh dinamakan model autoregresi rata-rata bergerak, disingkat ARMA(k,p), dengan persamaan
Karena AR(k) dan MA(p) adalah mode regresi deret waktu stasioner, maka ARMA(k,p) juga model regresi deret waktu stasioner.
Jika data tidak stasioner, maka dapat distasionerkan melalui proses stasioneritas, yang berupa proses diferensi jika trendnya linier, dan proses linieritas dengan proses diferensi pada data hasil proses linieritas, jika trend data tidak linier. Model ARMA(k,p) untuk data hasil proses diferensi dinamakan model autoregresi integrated rata-rata bergerak disingkat ARIMA(k,q,p).
Proses Analisis Data Deret Waktu
Dalam analisis data deret waktu, proses baku yang harus dilakukan adalah
Memetakan nilai atas waktu, hal ini dilakukan untuk menelaah kestationeran data, sebab jika data tidak stasioner maka harus distasionerkan melalui proses stasioneritas.
Menggambarkan korelogram (gambar fungsi autokorelasi), untuk menelaah apakah autokorelasi signifikan atau tidak, dan perlu tidaknya proses diferensi dilakukan. Jika autokorelasi data tidak signifikan, analisis data cukup menggunakan analisis regresi sederhana data atas waktu, sedangkan jika signifikan harus menggunakan analisis regresi deret waktu. Jika data ditransformasikan, maka proses pemetaan data dan penggambaran korelogram, sebaiknya dilakukan juga pada data hasil transformasi, untuk menelaah apakah proses transformasi ini sudah cukup baik dalam upaya menstasionerkan data.
Jika dari korelogram disimpulkan bahwa autokorelasi signifikan, maka bangun model regresi deret waktu dan lakukan penaksiran baik dalam kawasan waktu maupun kawasan frekuensi.
Lakukan proses peramalan dengan metode yang sesuai dengan kondisi data dan untuk mendapatkan hasil yang memuaskan sebaiknya gunakan metode Box-Jenkins.
Sasaran Analisis Data Deret Waktu
Ada beberapa tujuan dalam analisis data deret waktu diantaranya,
Deskripsi (description) : Jika ingin mempresentasikan karakter dari data yang dimiliki, seperti kestasioneran, keberadaan komponen musiman, keberartian autokorelasi, maka tahap pertama dari analisis data deret waktu adalah menggambarkan peta data dan korelogram, yang bertujuan :
Gambar peta data atas waktu untuk menelaah kestasioneran dan keberadaan komponen musiman dan
Gambar korelogram untuk menelaah signifikansi autokorelasi dan perlu-tidaknya transformasi data
Menerangkan (explanation) : Jika variabel data deret waktu lebih dari satu buah, maka telaahan dilakukan untuk menentukan apakah salah satu variabel dapat menjelaskan variabel lain, sehingga bisa dibangun sebuah model regresi (fungsi transfer) untuk keperluan analisis data deret waktu lebih lanjut. Sebab pada dasarnya data deret waktu adalah analisis data univariat, sehingga jika datanya bivariat atau multivariat, maka bagaimana proses univariatisasinya.
Perkiraan (prediction) : Jika dimiliki sampel data deret waktu dan diinginkan perkiraan nilai data berikutnya, maka proses peramalan harus dilakukan. Permalan adalah sasaran utama dari analisis data deret waktu, yang prosesnya bisa berdasarkan karakter dari komponen data atau model regresi deret waktu. Pengertian perkiraan (prediction) dan peramalan (forecasting) beberapa penulis ada yang membedakannya, sebab mereka berpendapat perkiraan adalah penaksiran (estimation) nilai dengan data dengan tidak memperhatikan model hubungan (regresi) antara nilai data, tetapi peramalan adalah proses penaksiran nilai data berdasarkan sebuah model hubungan fungsional antar nilai data. Tetapi kebanyakan penulis berpendapat perkiraan dengan peramalan adalah dua proses analisis data yang sama.
Kontrol (control) : Proses kontrol dilakukan untuk menelaah apakah model (regresi) ramalan (perkiraan) yang ditentukan cukup baik untuk digunakan ? Dalam statistika, sebuah model baik digunakan untuk peramalan, jika dipenuhi modelnya cocok dan asumsinya juga dipenuhi. Sehingga proses kontrol terhadap model perlu dilakukan untuk menelaah dipenuhi tidaknya asumsi, kecocokan bentuk model yang dibangun, ada-tidaknya pencilan (outliers), yang analisisnya dapat dilakukan berdasarkan karakter nilai residu atau analisis varians.
Untuk bisa memahami dengan baik mengenai analisis data deret waktu, diperlukan pemahaman mengenai analisis regresi biasa, sebab analisis data deret waktu adalah analisis khusus dari analisis regresi biasa, yaitu analisis regresi dalam hal data responnya berautokorelasi, sehingga konsepsi pada analisis regresi biasa berlaku dalam analisis regresi deret waktu, tetapi belum tentu untuk sebaliknya.
Pada artikel selanjutnya kita akan bahas secara teknikal penyelesaian data deret waktu dengan menggunakan analisis regresi deret waktu. SEMANGAT MEMPELAJARI!!!
Pada pembahasan sebelumnya kita sudah membahas secara konsep lag dan penerapannya pada model persamaan regresi. Salah satu yang telah kita bahas adalah model lag yang didistribusikan (distributed lag model), yang secara konsepsi diterapkan pada variabel bebas X. Pada kesempatan kali ini kita akan membahas satu model lain dari penerapan konsepsi lag, kali ini proses penerapannya dikenakan pada variabel tak bebas Y yang umum dikenal sebagai model Autoregresif (AR).
Model autoregresif (AR), mungkin umumnya dikenal khusus oleh para peneliti pada proses penerapan analisis data time series, dengan prosedur dan metode yang khusus. Pada pembahasan kali ini kita akan membahas secara mendasar pengembangan pemahaman dari fenomena lag, sedangkan pada pembahasan secara khusus terkait dengan analisis data time series kita akan paparkan pada kesempatan selanjutnya.
Penaksiran Model Autoregresif (AR)
Pada pembahasan penanganan data dengan model lag yang didistribusikan pada pendekatan lain yaitu Koyck dan rasionalisasinya dihasilkan model akhir penyelesaian yang mengandung unsur Autoregresif (AR). –peneliti dapat membaca pada buku Ekonometrik, Gujarati atau pembahasan artikel sebelumnya. Dimana semua model yang terbentuk memiliki bentuk umum sebagai berikut :
Model Autoregresif (AR) :
Model Koyck :
Model Harapan Adaptif :
Model Parsial :
Bentuk model persamaan di atas merupakan model yang memiliki sifat autoregresif (AR). Oleh karenanya, penaksiran pada model-model seperti di atas, kuadrat terkecil biasa (OLS) tidak dapat diterapkan secara langsung untuk model-model tersebut. Alasannya ada dua diantaranya variabel yang menjelaskan (X) yang bersifat stokastik (Yt-1) dan kemungkinan adanya serial korelasi (autokorelasi).
Seperti yang dijelaskan pada pembahasan terkait dengan asumsi regresi linear klasik terutama pada bahasan autokorelasi bahwa jika suatu variabel yang menjelaskan (X) dalam model regresi berkorelasi dengan unsur gangguan yang bersifat stokastik, maka penaksir OLS tidak hanya bias tetapi juga tidak konsisten, yaitu bahkan jika ukuran sampel meningkat secara tidak terbatas, penaksir tidak akan mendekati nilai populasi yang sebenarnya. Oleh karena itu, penaksiran model yang dibahas pada bahasan sebelumnya yaitu model Koyck dan model harapan adaptif dengan prosedur OLS biasa mungkin memberikan hasil yang menyesatkan secara serius.
Akan tetapi, model penyesuaian parsial berbeda. Dalam model penyesuaian parsial, penaksiran OLS dapat digunakan dan menghasilkan taksiran yang konsisten meskipun taksiran yang dihasilkan cenderung untuk bias (dalam sampel terbatas atau kecil). Meskipun dalam model Yt-1 tergantung pada ut-1 dan semua unsur disturbansi (gangguan sebelumnya), Yt-1 tidak berhubungan dengan unsur kesalahan saat ini ut. Oleh karena itu, selama ut bebas secara serial, Yt-1 akan juga bebas atau setidak-tidaknya tidak berkorelasi dengan ut, sehingga memenuhi satu asumsi penting dari OLS yaitu tidak ada korelasi antara variabel yang menjelaskan (X) dengan unsur gangguan (disturbansi yang stokastik, ut).
Meskipun pemakaian OLS dari model penyesuaian stok atau parsial (baca artikel : distributed lag model), memberikan taksiran yang konsisten karena struktur yang sederhana dari unsur kesalahan dalam model seperti itu, orang seharusnya tidak mengasumsikan bahwa model tadi lebih bisa diterapkan dibandingkan dengan model Koyck atau model harapan adaptif. Suatu model seharusnya dipilih atas dasar pertimbangan teoritis yang kuat, tidak hanya sekedar karena model tadi membawa ke penaksiran statistik yang mudah. Setiap model seharusnya dipertimbangkan atas baik buruknya sendiri, dengan memberikan perhatian pada gangguan stokastik yang muncul.
Mendeteksi Autokorelasi Dalam Model Autoregresif
Seperti kita lihat, nampaknya serial korelasi dalam kesalahan vt (bentuk ringkas faktor gangguan dalam model Koyck dan model harapan adaptif) yang membuat masalah penaksiran dalam model autoregresif (AR) agak kompleks. Dalam model penyesuaian stok unsur kesalahan vt tidak mempunyai serial korelasi (derajat pertama) jika unsur kesalahan ut dalam model yang asli tidak berkorelasi secara serial, sedangkan dalam model Koyck dan model harapan adaptif vt berkorelasi serial meskipun jika ut secara serial bebas (independen).
Seperti dalam pembahasan tentang pendeteksian autokorelasi, statistik d dari Durbin-Watson mungkin tidak bisa digunakan untuk mendeteksi serial korelasi (derajat pertama) dalam model autoregresif (AR), karena nilai d yang dihitung dalam model seperti itu biasanya mendekati 2, yang merupakan nilai d yang diharapkan dalam suatu urutan yang benar-benar random. Dengan perkataan lain, jika kita menghitung secara rutin statistik d untuk model seperti itu, terdapat bias yang terpasang di dalamnya melawan penemuan korelasi serial (derajat pertama). Meskipun demikian banyak peneliti menghitung nilai d karena menginginkan suatu yang lebih baik. Durbin sendiri telah mengusulkan suatu pengujian sampel besar dari korelasi serial derajat pertama dalam model autoregresif (AR). Pengujian ini disebut statistik h.
Statistik h memiliki ciri sebagai berikut :
Tidak penting berapa banyak variabel X atau beberapa banyak nilai lag dari Y yang dimasukan dalam model regresi. Untuk menghitung h, kita hanya perlu mempertimbangkan varians [var (α2)] dari koefisien lag Yt-1
Pengujian tidak bisa diterapkan jika [N var (α2)] melebihi 1.
Karena pengujian tadi dimaksudkan untuk sampel besar, penerapannya dalam sampel kecil tidak bisa dibenarkan secara tegas. Sifat sampel kecil dari pengujian tadi belum diterapkan sepenuhnya.
Pada prinsipnya kedua metode yang sudah diuraikan pada kesempatan kali ini yaitu model lag yang didistribusikan (distributed lag model) dan model autoregresif (AR) merupakan perluasan dari model regresi sederhana yang sudah dijelaskan secara terperinci pada artikel sebelumnya. Kedua model tersebut digunakan salah satunya adalah untuk mengatasi kendala autokorelasi yang terjadi pada model regresi klasik. Meskipun sedikit kompleks, uraian pada artikel ini boleh jadi dijadikan sebagai pengetahuan awal bagi peneliti yang hendak memperdalam metode yang lebih khusus yang berkaitan dengan data deret waktu atau time series data analysis. SEMANGAT MEMPELAJARI!!!
Pada artikel sebelumnya kita sudah membahas secara lengkap tentang regresi linear klasik baik secara konsep maupun pemenuhan terhadap asumsi-asumsi yang mendukung baiknya model regresi yang dihasilkan dari data yang kita miliki. Khususnya pada bahasan asumsi non autokorelasi pada model regresi linear kita sudah membahas mulai dari cara mendeteksi, konsekuensi jika terdapat aoutokorelasi hingga cara perbaikannya. Khusus pada poin tentang cara perbaikan pada model dengan masalah autokorelasi, dua cara yang dikemukakan adalah dengan skema autoregresif (AR) derajat pertama dikenal sebagai model persamaan perbedaan yang digeneralisasikan dan metode perbedaan pertama (the first difference method) sehingga model yang dibentuk dikenal sebagai model regresi rata-rata bergerak (moving average-MA).
Pada kesempatan kali ini kita akan mengulas konsepsi model autoregresif (AR) dan Lag yang didistribusikan (Distributed Lag) yang akan sangat bermanfaat dalam memahami konsep waktu pada suatu model.
Konsep Dasar Distributed-Lag-ModelDanModel Autoregresif
Dalam analisis regresi yang melibatkan data deret waktu, jika model regresi memasukan tidak hanya nilai variabel yang menjelaskan (X) saat ini, tetapi juga nilai masa lalu (lagged), model yang terbentuk disebut dengan model lagged yang didistribusikan (distributed-lag-model). Sedangkan jika model yang dibentuk dengan memasukan satu atau lebih nilai masa lalu (lagged) dari variabel tak bebas (Y) di antara variabel yang menjelaskan (X), model yang terbentuk disebut dengan model autoregresif (AR). Jadi,
Menyatakan model lag yang didistribusikan, sedangkan
Merupakan contoh dari model autoregresif.
Peran Waktu atau Lag Dalam Ilmu Ekonomi
Dalam ilmu ekonomi ketergantungan suatu variabel Y (variabel tak bebas) atas variabel lain X (variabel bebas) jarang bersifat seketika. Sangat sering, Y bereaksi terhadap X dengan suatu selang waktu. Selang waktu seperti itu disebut lag.
Misal :
“Seorang menerima kenaikan gaji sebesar 2000 dolar dalam gaji tahunan, dan misalkan bahwa ini merupakan peningkatan “permanen” dalam arti bahwa peningkatan gaji tersebut dipertahankan. Apakah pengaruh dari pendapatan ini atas belanja konsumsi tahunan orang tadi?
Sekarang merupakan pengalaman yang biasa bahwa setelah adanya peningkatan dalam pendapatan seperti itu, pada umumnya orang tidak bergegas untuk menghabiskan semua peningkatan tadi dengan segera. Jadi, orang yang menerima tadi bisa memutuskan untuk meningkatkan belanja konsumsi 800 dolar dalam tahun pertama setelah memperoleh peningkatan gaji sebagai pendapatannya, dengan 600 dolar yang lain tahun berikutnya, dan dengan 400 dolar lagi dalam tahun berikutnya, serta menabung sisanya. Pada akhir tahun ketiga, belanja konsumsi tahunan orang tadi akan meningkat 1800 dolar. Jadi kita dapat menuliskan fungsi konsumsi sebagai,
Dimana Y adalah belanja konsumsi dan X adalah pendapatan
Persamaan di atas, menunjukkan bahwa pengaruh peningkatan dalam pendapatan 2000 dolar tersebar, atau didistribusikan untuk 3 periode tahun. Oleh karena itu model tersebut dinamakan model lag yang didistribusikan (distributed lag model) karena pengaruh dari suatu sebab tertentu (pendapatan) tersebar selama sejumlah periode waktu. Secara lebih umum kita bisa menuliskan,
Dan,
Disebut multiplier lag yang didistribusikan jangka panjang atau total.
Dari persamaan yang diperoleh kita lihat bahwa kecenderungan marjinal jangka pendek untuk konsumsi (MPC) adalah 0,4 dan kecenderungan marjinal konsumsi jangka panjang adalah 0.4 + 0.3 + 0.2 = 0.9. Artinya bahwa mengikuti kenaikan satu dolar dalam pendapatan, konsumen akan meningkatkan tingkat konsumsinya kira-kira 40 sen dalam tahun peningkatan pertama, 30 sen lainnya dalam tahun berkutnya dan 20 sen lagi dalam tahun berikutnya. Jadi dampak jangka panjang dari kenaikan pendapatan satu dolar adalah 90 sen.
Alasan Lag
Ada tiga alasan utama kenapa lag terjadi, diantaranya
Alasan Psikologis. Disebabkan oleh kekuatan kebiasaan, orang tidak mengubah kebiasaan konsumsi mereka dengan segera mengikuti penurunan harga atau peningkatan pendapatan mungkin karena proses perubahan melibatkan suatu kehilangan kegunaan yang segera.
Jadi orang yang mendadak jadi jutawan karena memenangkan lotre, mungkin tidak merubah cara hidup yang telah terbiasa baginya untuk waktu yang lama karena mereka mungkin tidak tahu bagaimana berreaksi terhadap keberuntungan yang tidak disangka (windfall gain), dengan segera. Tentu saja, dengan waktu yang cukup, mereka dapat belajar untuk hidup dengan keberuntungan yang baru saja diterima. Juga, mungkin orang tahu apakah suatu perubahan adalah “permanen” atau “sementara”. Jadi, reaksi terhadap peningkatan dalam pendapatan akan tergantung pada apakah peningkatan tadi bersifat permanen atau sementara. Jika ini hanya peningkatan untuk sekali saja dan dalam periode berikutnya pendapatan kembali ke tingkat sebelumnya, saya akan mungkin menabung seluruh peningkatan pendapatan tadi, sedangkan orang lain dalam posisi saya, mungkin memutuskan untuk menikmatinya sepuas-puasnya.
Alasan yang bersifat teknologi. Misalkan harga modal dibandingkan dengan tenaga kerja relatif menurun, yang menyebabkan subtitusi (pengganti) modal untuk tenaga kerja secara ilmu ekonomis dimungkinkan. Tentu saja, penambahan dalam modal memerlukan persiapan waktu (masa persiapan). Lebih jauh lagi, jika penurunan dalam harga diharapkan hanya bersifat sementara, perusahaan mungkin tak bergegas-gegas untuk menggantikan modal untuk tenaga kerjanya, terutama jika mereka mengharapkan setelah penurunan harga modal yang bersifat sementara mungkin akan meningkat di atas tingkat sebelumnya. Kadang-kadang pengetahuan yang tidak sempurna juga menyebabkan terjadinya lag.
Pada saat ini pasar untuk kalkulator saku elektronik jenuh dengan semua jenis kalkulator dengan berbagai ciri perhitungan dan harga. Lebih jauh lagi, sejak diperkenalkandi akhir tahun 60-an, harga dari sebagian besar kalkulator telah turun secara dramatis. Sebagai hasilnya, calon konsumen untuk kalkulator mungkin ragu untuk membelinya sampai mereka mempunyai waktu untuk melihat ciri-ciri dari harga semua merek yang bersaing. Lebih jauh lagi, mereka ragu untuk membeli karena berharap ada penurunan lebih lanjut dalam harga atau pembaharuan-pembaharuan yang bermanfaat.
Alasan-alasan kelembagaan. Alasan ini juga menyumbangkan terjadinya lag. Misalnya, kewajiban yang bersifat kontrak mungkin mencegah perusahaan untuk beralih dari satu sumber tenaga kerja atau bahan mentah ke yang lainnya.
Sebagai contoh, mereka yang telah menempatkan dana dalam tabungan bank jangka panjang untuk periode waktu yang tetap seperti 1 tahun, 3 tahun atau 7 tahun, pada dasarnya terkunci meskipun kondisi pasar uang mungkin sedemikian rupa sehingga pendapatan yang lebih tinggi tersedia di tempat lain. Serupa dengan itu, majikan seringkali memberikan pada karyawan suatu pilihan di antara beberapa rencana asuransi kesehatan, tetapi sekali pilihan telah dibuat, seorang karyawan mungkin tidak bisa berpindah ke rencana lain untuk sekurang-kurangnya 1 tahun. Meskipun hal ini dilakukan untuk kemudahan administratif, karyawan tadi terkunci untuk 1 tahun.
Penaksiran Model Lag Yang Didistribusikan (Distributed Lag Model)
Dengan mempercayai bahwa model yang didistribusikan memainkan peranan yang sangat berguna dalam ilmu ekonomi, bagaimana orang menaksir model seperti itu? Khususnya misalkan kita memiliki model yang didistribusikan dalam satu variabel yang menjelaskan berikut :
Karena variabel yang menjelaskan Xt diasumsikan nonstokastik (atau setidak-tidaknya tidak berkorelasi dengan unsur gangguan ut), Xt-1, Xt-2 dan seterusnya juga nonstokastik. Oleh karena itu, pada prinsipnya, kuadrat terkecil biasa (OLS) dapat diterapkan terhadap persamaan di atas. Ini merupakan pendekatan yang diambil oleh Alt dan Tinbergen. Mereka menyarankan bahwa untuk menaksir persamaan lag yang didistribusikan orang bisa melangkah maju secara berurutan (stepwise) yaitu mula-mula meregresikan Yt atas Xt, kemudian meregresi Yt atas Xt dan Xt-1, kemudian meregresi Yt atas Xt, Xt-1 dan Xt-2, dan seterusnya. Prosedur yang berurutan ini berhenti ketika koefisien regresi dari variabel lag mulai menjadi tidak penting (tidak signifikan) secara statistik dan atau koefisien dari setidak-tidaknya satu variabel berubah tanda dari positif ke negatif atau sebaliknya. Mengikuti aturan ini, Alt meregresikan konsumsi untuk minyak bakar Y atas pesanan baru X. Didasarkan pada kuartalan untuk periode 1930 s.d 1939, hasil analisanya sebagai berikut :
Alt memilih regresi kedua sebagai “yang terbaik” karena dalam dua persamaan yang terakhir dari Xt-2 tidak stabil dan dalam persamaan terakhir tanda dari Xt-3 adalah negatif, yang mungkin sulit untuk diinterpretasikan secara ekonomi.
Meskipun nampaknya jelas, penaksiran-khusus memiliki banyak kelemahan, seperti berikut ini :
Tidak ada petunjuk apriori mengenai panjang maksimum lag
Begitu orang menaksir lag yang berurutan, semakin sedikit derajat kebebasan yang tersisa, yang membuat kesimpulan secara statistik, agak goyah. Ahli ekonomi biasanya tidak begitu beruntung untuk mempunyai serangkaian data yang panjang sehingga mereka dapat melanjutkan mengestimasi banyak lag.
Lebih penting lagi, dalam data deret waktu ekonomis, nilai yang berurutan (lag) cenderung untuk sangat berkorelasi; jadi multikolinearitas akan nampak. Sehingga hasilnya, kita mungkin cenderung untuk menyatakan (secara salah) bahwa suatu koefisien lagged tidak penting (signifikan) secara statistik. Tetapi ketidak pentingan secara statistik ini mungkin disebabkan karena multikolinearitas dan bukan karena kenyataan bahwa koefisien benar-benar tidak penting.
Dari masalah pandangan tadi, prosedur penaksiran ad-hoc tidak begitu disarankan. Jelas beberapa pertimbangan sebelumnya atau pertimbangan teoritis harus dilakukan untuk berbagai β jika kita akan melangkah maju dengan masalah penaksiran.
Terdapat beberapa pendekatan yang lain selain pendekatan penyelesaian yang sudah diuraikan di atas dalam rangka mencari solusi terbaik yang dapat menghasilkan model yang dapat memberikan nilai prediksi terbaik. Beberapa yang dapat menjadi telaah lanjutan bagi peneliti diantaranya : (1) Pendekatan Koyck Untuk Model Lag Yang Didistribusikan, (2) Rasionalisasi Model Koyck : Model Harapan Adaptif (Adaptive Expectation Model), dan (3) Rasionalisasi Lain Dari Model Koyck : Model Penyesuaian Stok atau Model Penyesuaian Parsial.
Pada prinsipnya ketiga pendekatan lain di mulai dari pendekatan Koyck dan beberapa rasionalisasinya bertujuan bahwa tiap koefisien β yang berurutan secara angka lebih kecil dari β sebelumnya, yang mengandung arti bahwa jika orang kembali ke periode lalu yang jauh, pengaruh dari lag tadi terhadap Yt secara progresif menjadi semakin kecil (secara pasti didapatkan melalui perumusan di awal perhitungan pembentukan model). Selain itu, yang di perhatikan juga adalah terhindarnya model dari masalah autokorelasi dan multikolinearitas.
Pada kesempatan yang lain kita akan bahas konsep dasar dari model autoregresif (AR) sebagai pembanding dari model lag yang didistribusikan. Pembangunan pemahaman terhadap konsep di atas sangat penting ketika melakukan proses analisis data deret waktu (time series) secara lebih khusus yang akan di bahas pada artikel berikutnya. SEMANGAT MEMPELAJARI!!!
Pada kesempatan kali ini kita akan sharing pengalaman kita di lapangan, survey lapangan atau sebar kuesioner, yang berbeda dengan sharing pada kesempatan sebelumnya. Survey lapangan atau sebar kuesioner kali ini, hendak menggali informasi atau perspektif dari pengurus Koperasi di Kota Bandung, tepatnya informasi atau perspektif para pengurus Koperasi dalam hal management baseZach’s Star of Succes. Sekali lagi bahwa persiapan fisik maupun pengetahuan terhadap medan lapangan yang akan dijadikan sasaran pengambilan data haruslah diperhatikan. Karena banyak hal-hal yang tidak bisa kita prediksikan dapat terjadi dan menjadi tantangan tersendiri di lapangan.
Objek dari survey lapangan atau sebar kuesioner lapangan kali ini dalam kategori gampang-gampang susah. Target spesifik yang menjadi kriteria dari responden adalah pengurus Koperasi di Kota Bandung. Kategori gampang-gampang susah di sini, “gampang” karena merupakan organisasi non pemerintah sehingga prosedural birokrasi relatif bisa diabaikan dan “susah” karena hunting untuk mendapatkan lokasi target sampel butuh perjuangan luar biasa.
Crew lapangan yang diturunkan pada survey lapangan kali ini sebanyak 2 orang. Rata-rata tenaga yang kita pakai berusia antara 20 s.d 25 tahun. Selain muda semangatnya pun OK untuk menjaga kualitas hasil survey yang kita lakukan. Selain itu, crew yang well educated (rata-rata sedang menempuh perkuliahan) memberikan nilai plus tersendiri, selain dari pola bahasa dalam komunikasi yang baik, yang terpenting behave yang menyenangkan bagi responden kita.
Proses survey yang sangat challenging yang tim kita temui di lapangan, wellplanning dan well strategy dalam melakukan survey lapangan kali ini sangat diperlukan sekali, sekali lagi cost and time effective dalam penelitian. Calon responden yang kita hadapi adalah responden memiliki kecenderungan untuk menolak sangat tinggi dikarenakan frame bermanfaatnya research menjadi tantangan tersendiri di lapangan. Benefit first. Prosedural, karena yang kita datangi merupakan institusi bisnis kelengkapan permohonan perijinan perlu dipersiapkan oleh tim lapangan untuk mempermudah proses komunikasi dan legalitas.
Biaya dan Waktu, yang kita temui di lapangan dikarenakan birokrasi oleh karena ada jeda waktu tunggu yang lumayan untuk memperoleh kepastian “bisa ikut berpartisipasi” dan atau “tidak bisa ikut berpartisipasi”, otomatis menjadi estimasi budget tambahan yang harus dipersiapkan. Effort Tim Lapangan, jarak tempuh, kondisi serta situasi alam yang menjadi tantangan tersendiri bagi tim lapangan, diperlukan tim tangguh di lapangan.
Saran kita berdasarkan pengalaman di lapangan diperlukan extra time untuk melakukan penelitian dengan kriteria responden dari institusi bisnis seperti Koperasi. Rencana time line research yang harus well planning dan well organized. Networking atau Offering Benefits mungkin bisa jadi instrumen yang dapat mempermudah dan mempercepat dalam proses pengambilan data lapangan.
Sharing singkat ini, semoga bermanfaat dalam membantu rekan-rekan peneliti dalam membangun frame awal sebelum melakukan survey di lapangan. Kami akan share banyak pengalaman kami di lapangan pada kesempatan yang lain. SEMANGAT MENELITI!!!
Pada kesempatan kali ini kita akan sharing pengalaman kita di lapangan, survey lapangan atau sebar kuesioner, yang berbeda dengan sharing pada kesempatan sebelumnya. Survey lapangan atau sebar kuesioner kali ini, hendak menggali informasi atau perspektif dari sales atau marketing hotel berbintang di Kota BANDUNG, tepatnya informasi atau perspektif para sales atau marketing dalam hal inovasi marketing dalam mendatangkan tamu hotel. Sekali lagi bahwa persiapan fisik maupun pengetahuan terhadap medan lapangan yang akan dijadikan sasaran pengambilan data haruslah diperhatikan. Karena banyak hal-hal yang tidak bisa kita prediksikan dapat terjadi dan menjadi tantangan tersendiri di lapangan.
Objek dari survey lapangan atau sebar kuesioner lapangan kali ini dalam kategori sangat kompleks. Target spesifik yang menjadi kriteria dari responden adalah sales atau marketing hotel berbintang di Kota BANDUNG. Kategori kompleks di sini adalah dimulai dari prosedural, biaya dan waktu serta effort tim lapangan.
Crew lapangan yang diturunkan pada survey lapangan kali ini sebanyak 1 orang. Crew yang well educated, bermental OK, PeDe, memiliki komunikasi yang baik dan behave yang menyenangkan bagi responden. Karena yang kita temui dilapangan mulai dari level staff, leader sampai dengan level manager hotel. So, right person is a must.
Proses survey yang sangat challenging yang tim kita temui di lapangan, wellplanning dan well strategy dalam melakukan survey lapangan kali ini sangat diperlukan sekali, sekali lagi cost and time effective dalam penelitian. Calon responden yang kita hadapi adalah responden memiliki kecenderungan untuk menolak sangat tinggi dikarenakan frame bermanfaatnya research dan traffic kerja di perhotelan menjadi tantangan tersendiri di lapangan. Benefit first. Prosedural, karena yang kita datangi merupakan institusi bisnis kelengkapan permohonan perijinan hingga proposal research perlu dipersiapkan oleh tim lapangan, remember Birokrasi.
Biaya dan Waktu, yang kita temui di lapangan dikarenakan birokrasi oleh karena ada jeda waktu tunggu yang lumayan untuk memperoleh kepastian “bisa ikut berpartisipasi” dan atau “tidak bisa ikut berpartisipasi”, otomatis menjadi estimasi budget tambahan yang harus dipersiapkan. Effort Tim Lapangan, jarak tempuh, kondisi serta situasi alam yang menjadi tantangan tersendiri bagi tim lapangan, diperlukan tim tangguh di lapangan.
Saran kita berdasarkan pengalaman di lapangan diperlukan extra time untuk melakukan penelitian dengan kriteria responden dari institusi bisnis besar. Rencana time line research yang harus well planning dan well organized. Networking atau Offering Benefits mungkin bisa jadi instrumen yang dapat mempermudah dan mempercepat dalam proses pengambilan data lapangan.
Sharing singkat ini, semoga bermanfaat dalam membantu rekan-rekan peneliti dalam membangun frame awal sebelum melakukan survey di lapangan. Kami akan share banyak pengalaman kami di lapangan pada kesempatan yang lain. SEMANGAT MENELITI!!!